案例4_优酷
本节你可以学到: 当页面并非标准列表时,如何快速获取网页信息。如列表根路径。
1.优酷列表
有朋友给我反馈,对于这个页面,手气不错不能得到合适的结果:
http://game.youku.com/index/lol
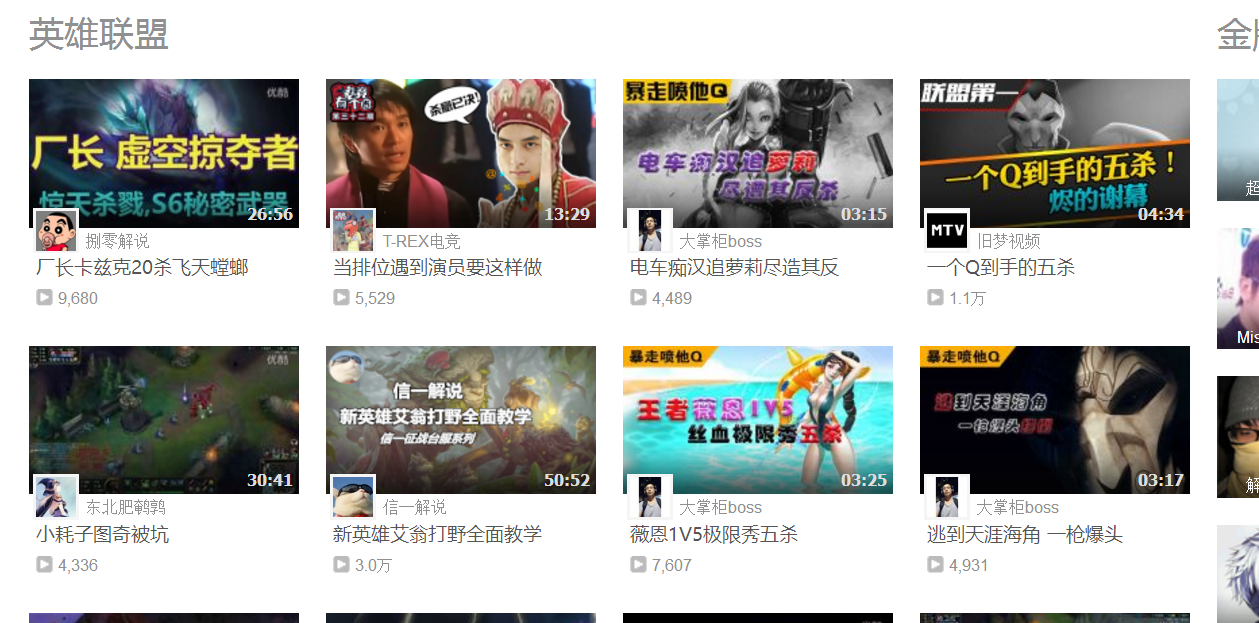
不论如何,手气不错只能显示一列7个元素,而不能获取全部的28个元素,这可如何是好?
仔细一看,原来整个网页的结构是这样的:
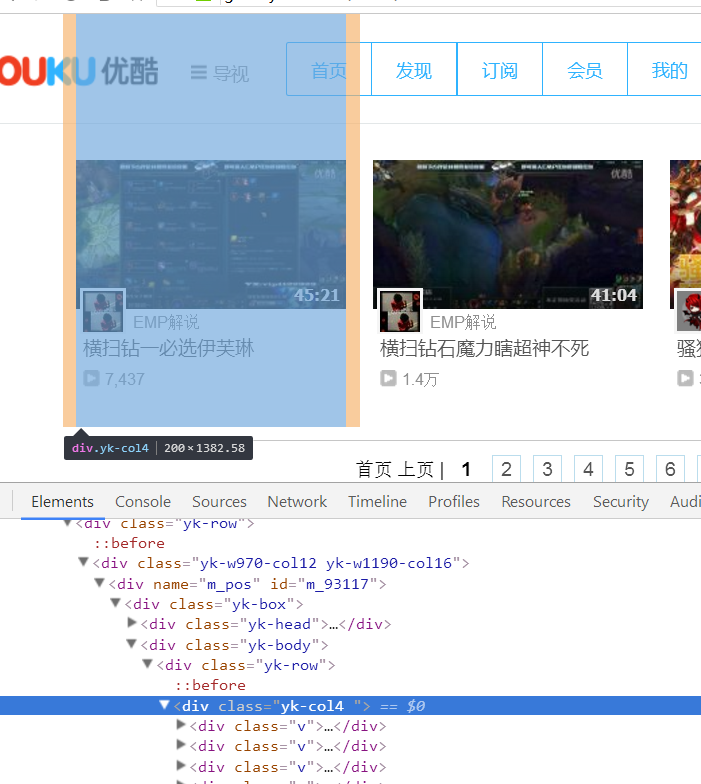
原来,它每一列为一个div,每个div里有7个元素。这样,手气不错只会检测到这个父div,而无法获取全部4*7=28个元素。
怎么办呢?手工填写列表根路径就可以。(您可以先尝试本教程,然后阅读3.2采集器高级用法)
我们观察到,每个包含视频元素的div,都是这样的
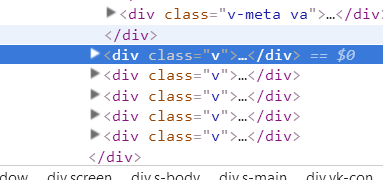
因此,它们的xpath应当是 //*[@class="v"] ,什么?不懂?复习XPath语法去。
这样,我们将上面的表达式拷贝到Hawk的列表根路径上,使用手气不错:
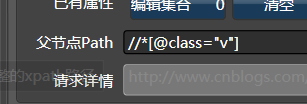
哈哈,是不是所有的元素都获得啦?
2.总结一下
当你提供列表根路径时,手气不错就会省略执行寻找列表节点的过程。
- 第一步,Haw会根据列表根路径,获取所有节点。
- 之后会在这些节点上,进行diff操作,获取所有属性。
这样,即使是更复杂的页面,通常目标节点都有很多特定的特征(如class和id,甚至其他标签),那么,总可以通过xpath语法,将其快速筛选出来。