数据清洗
数据清洗是一种任务,包括几十个子模块, 这些子模块包含四类:生成, 转换, 过滤和执行。
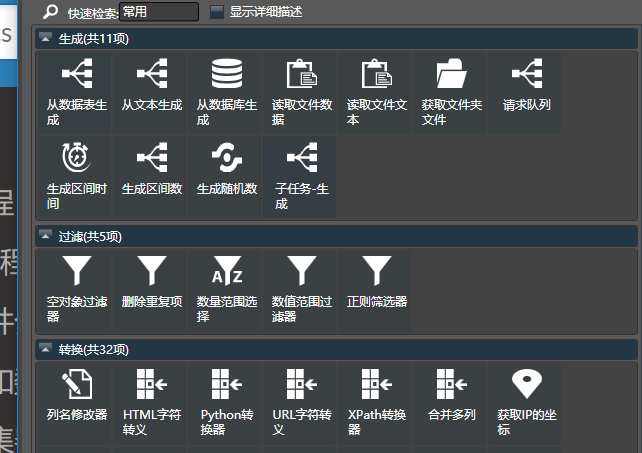
在输出的文档中,点击单元格,可以放大和显示该单元格的文本内容(相比于Hawk早期版本,这实在太实用了):
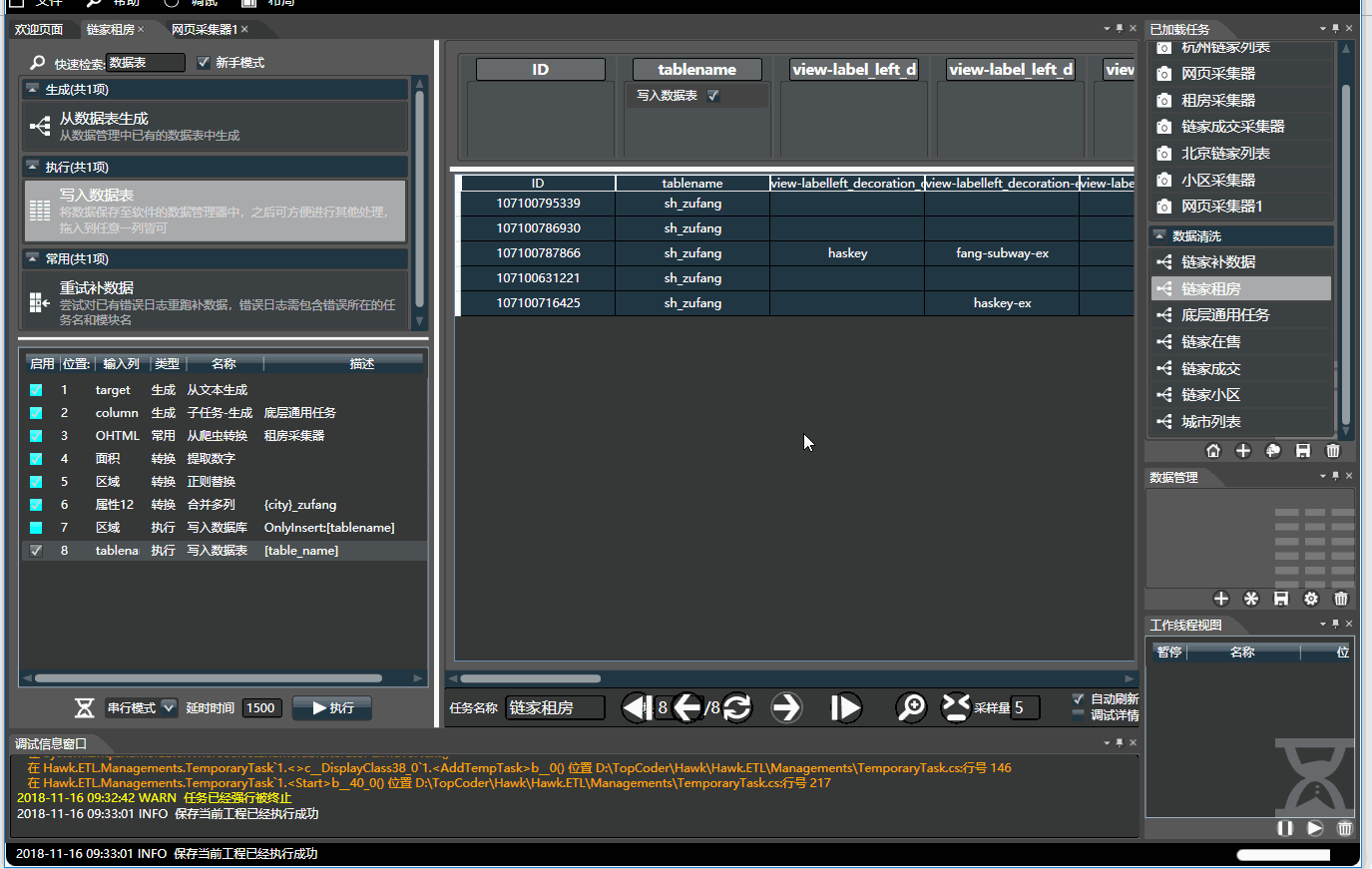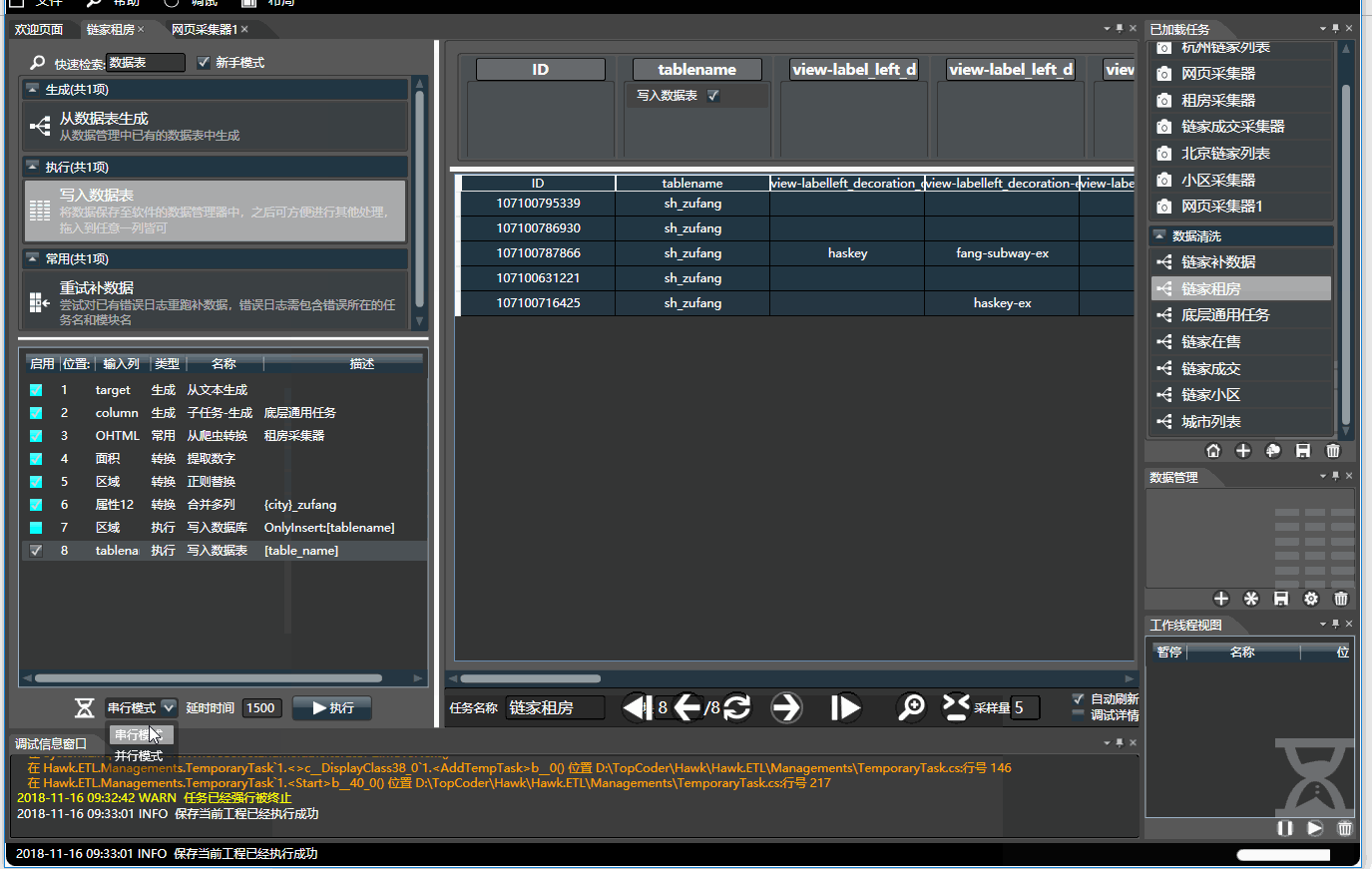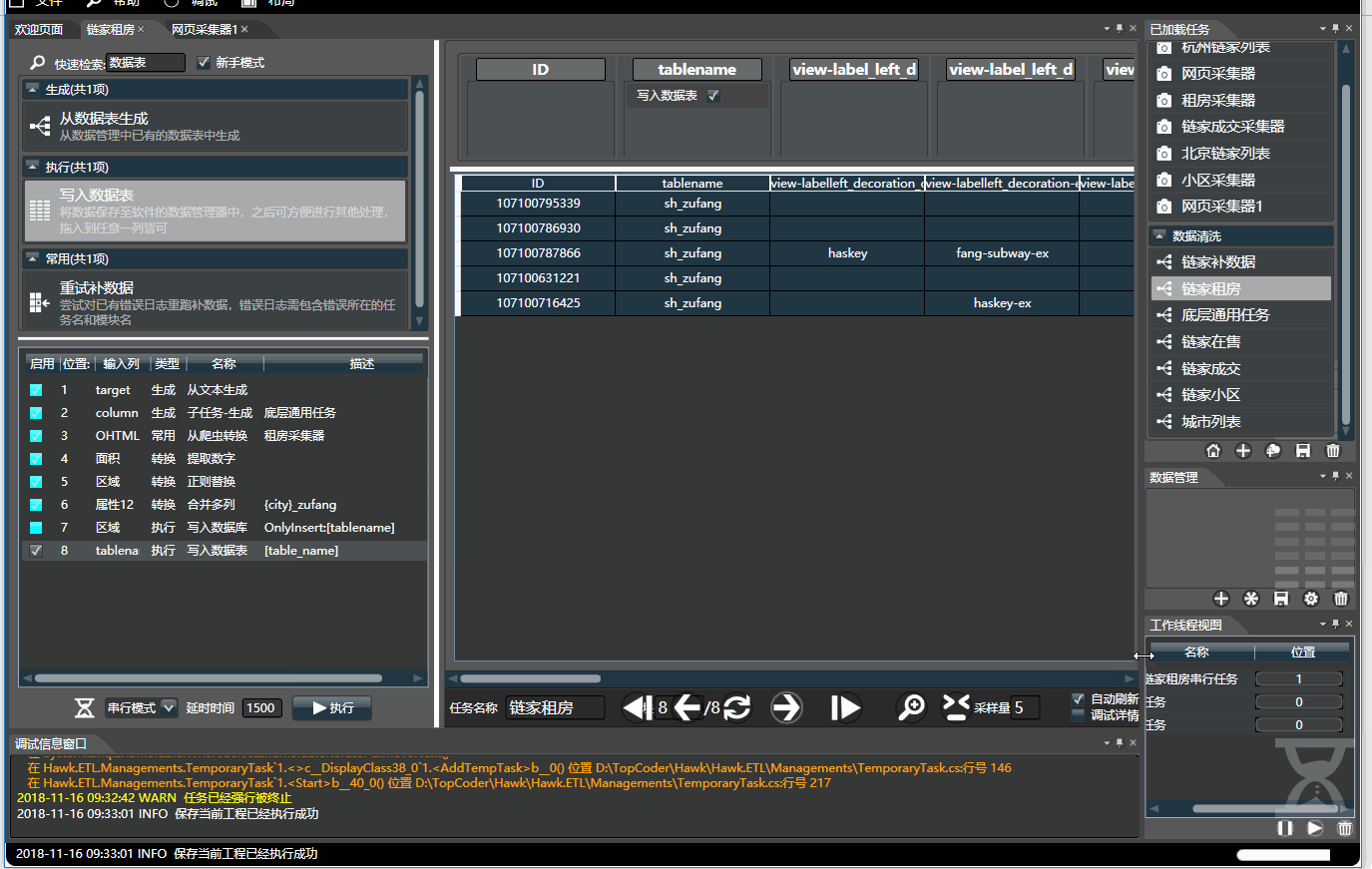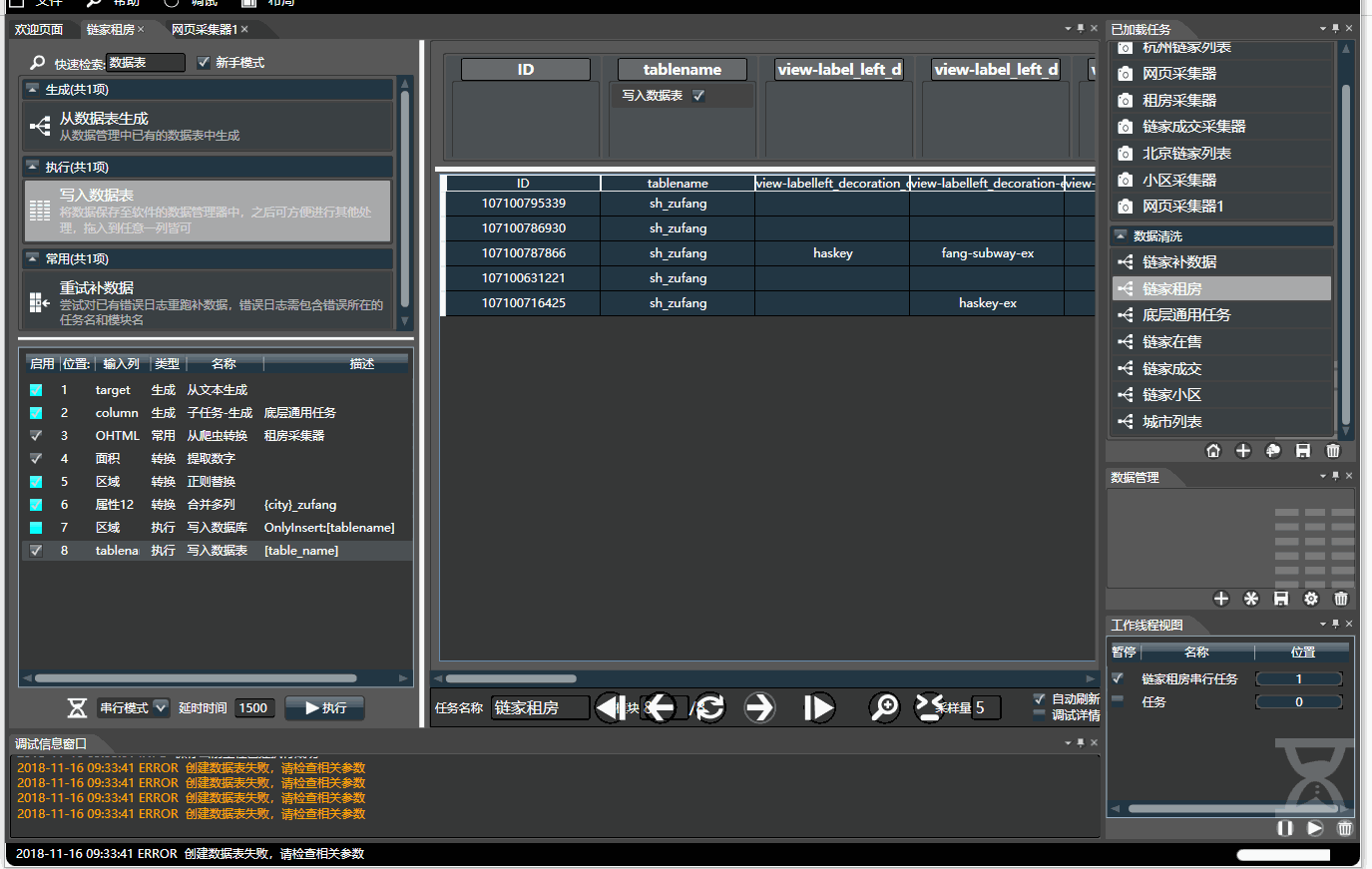
1.快速使用说明
数据清洗可以通过组合多个不同的子模块,生成多样的功能,通过拖拽构造出一个工作流,它能够产生一个有限或无限的文档序列。比如下面:
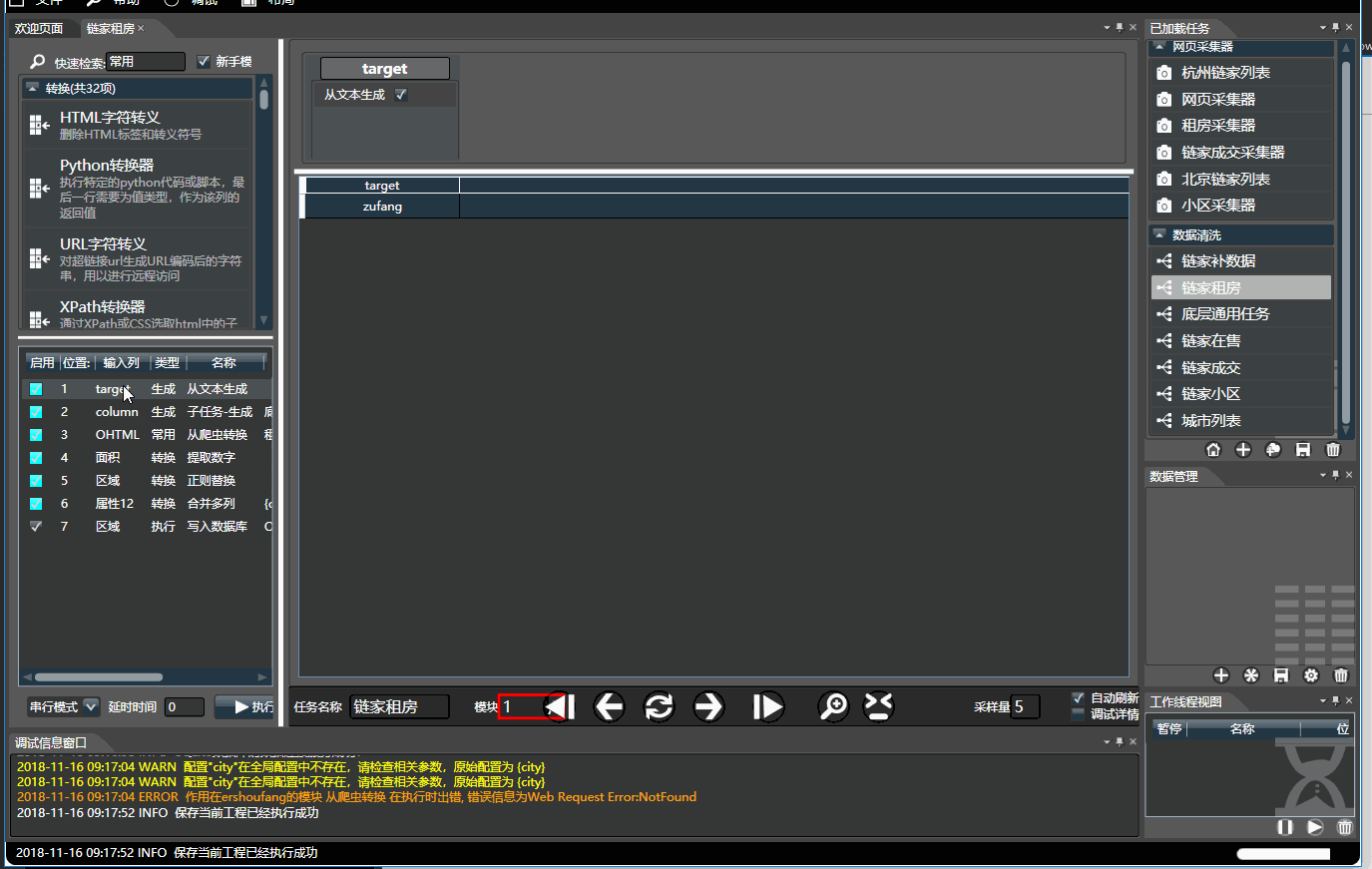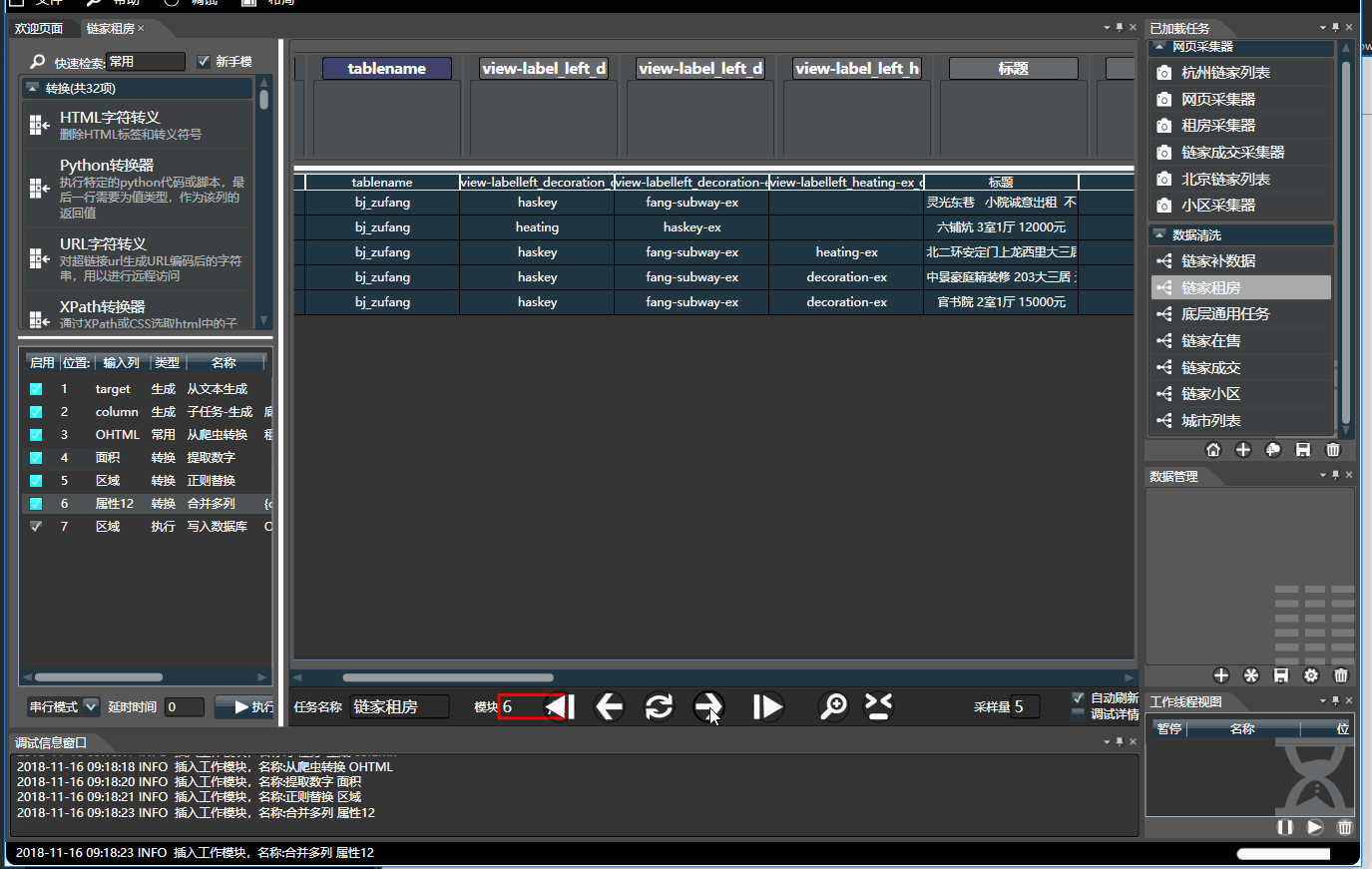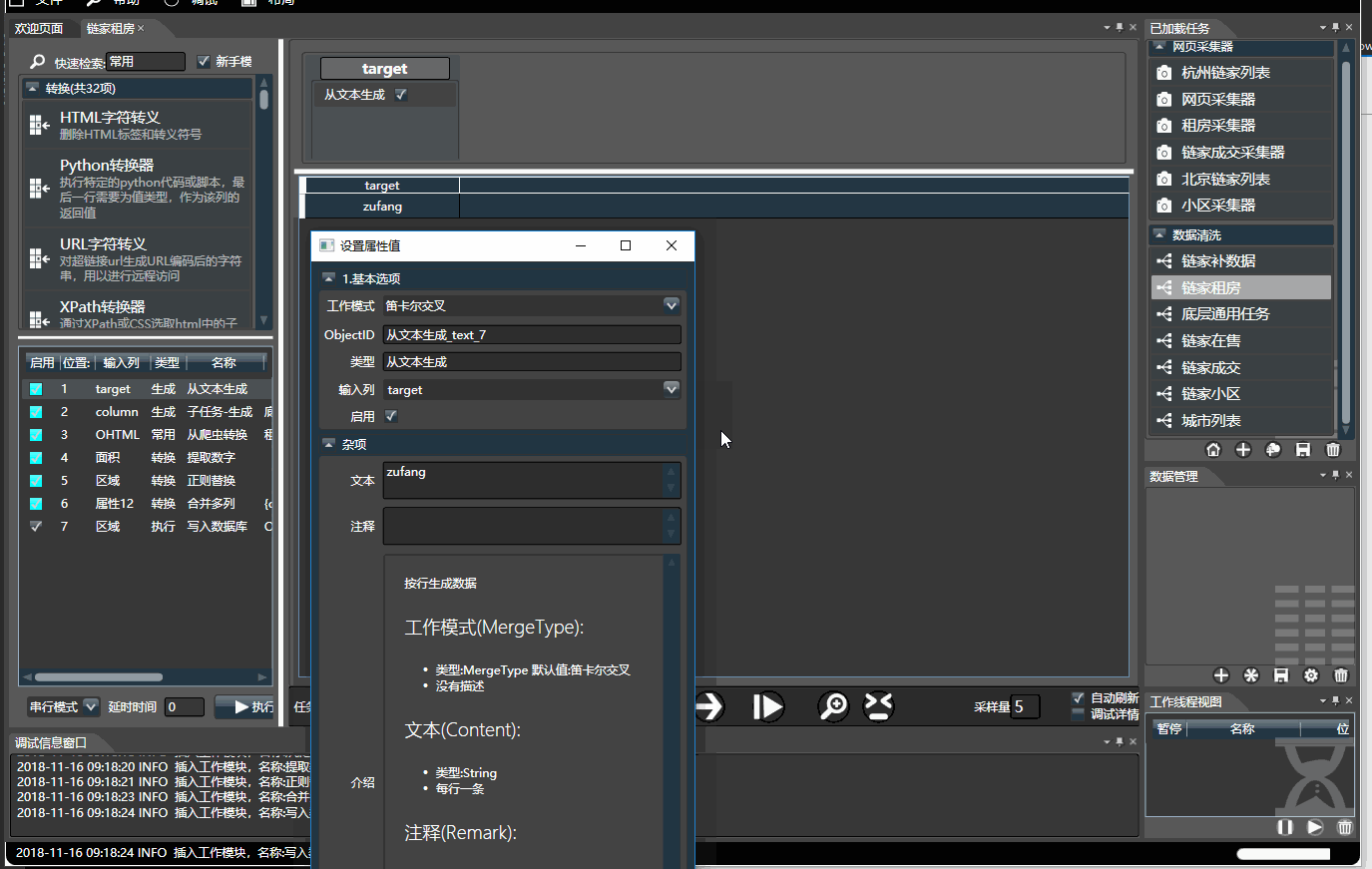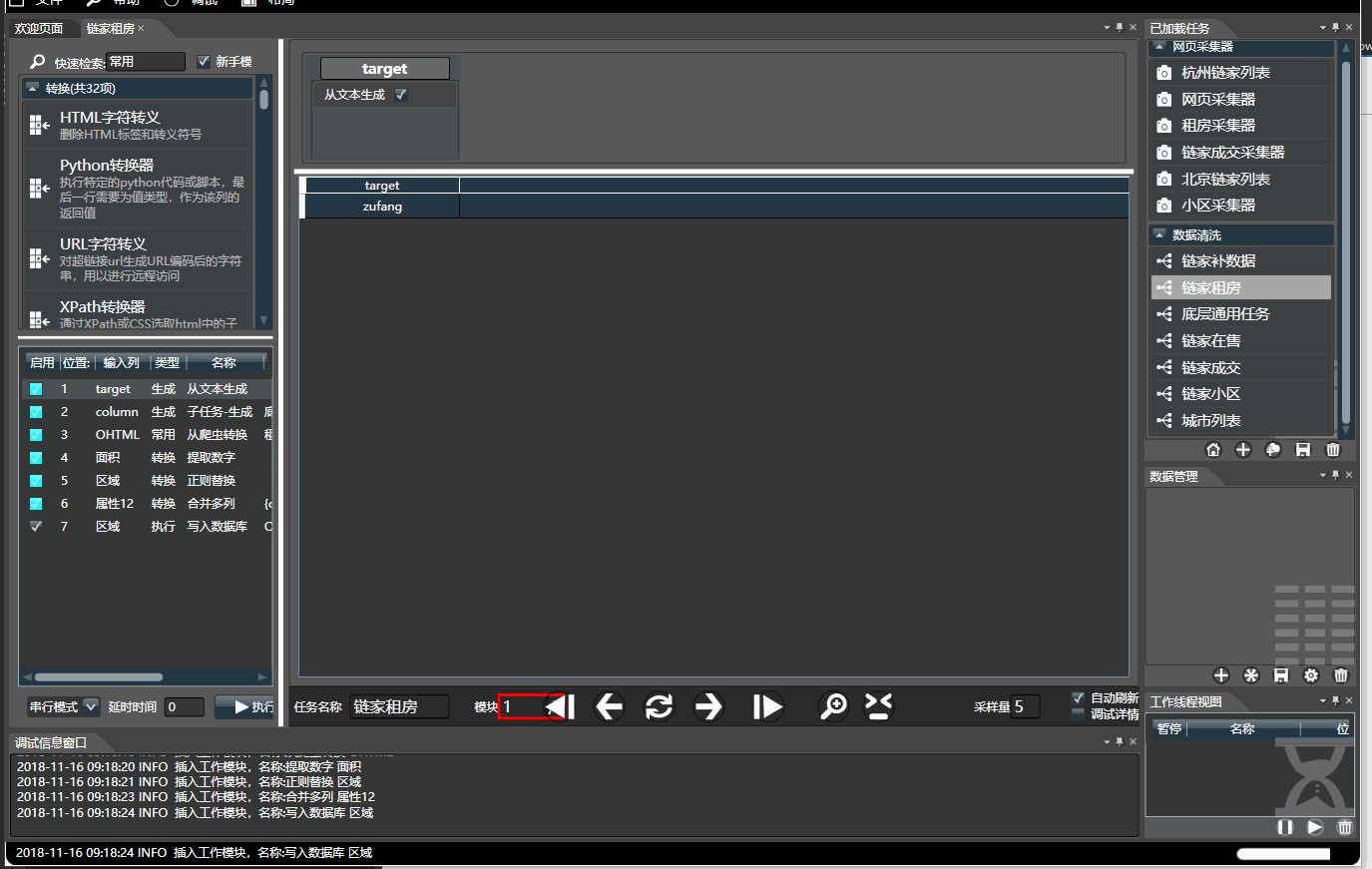
1.1.基本操作
- 左侧是所有模块列表,分为生成,转换,过滤和执行四种类型,可通过名称和拼音首字母快速检索。顺序组合可构成复杂任务。
- 右侧是数据预览,可将左侧选中的模块拖入到右侧对应列上。 双击每个列上面的模块对其配置。将鼠标停靠字段上可查看使用介绍
- 预览时,处理是串行的,数据不会被写入,有缓存,调试所见即所得。 只有在执行模式下才会并行快速执行。
- 执行器可看做带有副作用(如写入文件)的转换器,只有在执行时才会运行
- 生成器通常位于任务开头,可从文本,文件,数据库读取数据。生成器也能位于流的中间,通过多种模式与已有数据流组合
- 下方菜单栏可点击刷新,前后单步,可通过采样量来修改预览的数据量。配置完毕无误后,左侧面板点击执行即可。
- 很多问题来自于模块顺序不对,任何步骤错误,会导致连锁的问题,因此有必要使用单步调试,在调试到某步时,拖入的模块会插入到所在位置。
1.2.高级功能和技巧
- 输入列一般不用配置,需要时可下拉选择,也可手工输入文本。列名不要为纯数字,否则无法正常显示。
- 关于Python转换器:最后一行必须是可求值的表达式。例如有两列a,b,转换器输出列为c,表达式为a+b,则c列内容就是a+b。但表达式不能写c=a+b; Python是强类型语言,输入的数据可能是字符串或数字,因此必要时需要做类型转换;通过填写库路径,可让转换器调用第三方模块。
- 可在任务的各个位置拖入多个执行器(如【写入数据表】),它保存的是当前状态的数据。
- 子任务:任务可互相调用,功能非常强大,可用于处理多次跳转,详情页还包含列表的问题,比较复杂,需参考相关文档。
2.几种模块的介绍
2.1.转换器
转换器是最为常用的一种类型,当然它的使用也是最复杂的。
转换器有三种子类型:
- ColumnUDF: 单文档: 只对一个列有效,如
提取数字, - UDF: 单文档:如删除该列,它仅涉及文档内部的修改,可能会影响多个列
- UDAF: 多文档:典型的如 多文档模式下从爬虫转换,每一行url都可能生成20个甚至更多的文档,它的行为cross(交叉)模式下的生成器。
ColumnUDF是UDF的特例, UDF是UDAF的特例(只产生一种)
绝大多数转换器都是UDF类型。但同一个转换器在不同的配置下,可能会有多种行为,例如从爬虫转换,如果选择的 网页采集器 为单文档(单文档)模式,则该转换器为UDF模式,若为 多文档模式,则为UDAF模式。
- 输入列: 就是要输入这个模块的列,(Hawk1时代也称作原列名);
- 输出列: 则指的是模块输出的列。 UDF模式下,如果新列名为空,则新列名等于原列名,直接修改在原始列上。
2.2.关于UDAF的必要说明
当你使用多文档模式的爬虫,或单转多时,虽然生成了多个文档,但原始的数据(如URL)不见了。这是因为Hawk丢弃了这些列。
经过大量实践,如果不这么做,每个新数据后面,都会跟上原始的老数据,如果1转20,则老数据会重复生成20次,这是没有必要的。有时不得不拖入大量的删除该列来处理。
当然,有时转换时需要包含原始数据的部分列,则可在转换器的新列名中填写要鲤鱼跳龙门的列的名称,中间用空格分割。
- 在Hawk3中,还支持在新列名中输入
*号,此时所有的原始列都会添到新的文档之中。 - 注意,UDAF的新列可能会覆盖掉原始列的数据,因此多检查列名,避免意料之外的覆盖
转换器有几种工作模式:
- 多文档 :生成多条数据(文档)
- 单文档 : 单文档
- 不进行转换: 按照原始数据返回
2.3.过滤器
过滤器可以在流中,过滤掉不符合条件的文档(也就是横向过滤)。
- 可勾选
反向,此时只会留下不符合条件的文档。即对原始结果做了取反。 - 如何对列过滤? 目前Hawk并未提供该功能,可通过拖入多个删除该列来实现
Hawk3的过滤器还支持几种不同的行为,即过滤模式,分别是:
- 按行过滤
- 成功后通过之后的所有行
- 失败后通过之后所有行
2.4.执行器
执行器是负责将Hawk的结果传送到外部环境的工具。 你可以写入数据表,数据库,甚至执行某个特定的动作,或是生成文件等等。 在调试模式下,执行器都是不工作的。这是为了避免产生副作用。否则,每刷新一遍数据,就会向数据库中写入,这显然是不可接受的。 只有在运行模式下,才会使执行器生效。
2.5.生成器
顾名思义,生成器就是通过一定的参数,生成一个文档列表的组件。生成器通常位于任务开头,可从文本,文件,数据库读取数据。 或者从一个区间内生成纵向的数字和时间。
它与转换器有很多相似之处,但是明显不同:
- 转换器必须有输入,而生成器不需要。生成器一般需要输出列,来保存其输出的数据。
- 生成器输出的数据可以与原始数据进行横向/纵向/交叉拼接,这远比转换器灵活
- 生成器的参数都支持方括号语法,但转换器只有部分支持
当生成器生成数据后,如何与原始的数据组合呢?有四种模式:
- 按行纵向合并
- 笛卡尔交叉
- 交错交叉
- 按列横向合并

拖入的模块顺序是非常重要的,一个常见问题是顺序不对,导致生成的数据不符合预期。数据清洗可通过 从爬虫转换 来调用 网页采集器 ,也可以通过子任务来调用其他数据清洗,是组合各种模块和任务的工厂。
Hawk的各类模块中包含大量配置,其写法统一总结如下:
- 具体数值,直接填入配置框即可
- 涉及到输入多个列名,多个分隔符等,都默认用空格分割,例如
a b c - 当希望从本
数据清洗中读取其他列的数据到本参数,使用方括号表达式,例如[col] - 当希望从全局配置中读取特定字段时,使用大括号表达式,例如
{YOUR_CONFIG} - 希望将多个列的数据合并作为参数时,可先使用
合并多列,再使用对应的表达式 - 配置子任务的模块范围时:
1:100表示从1到100,2:-2表示从第2个模块到倒数第二个模块,可参考Python的slice写法 - 配置子任务的字段映射时,可以用
a:b c:d表示a列映射到b列,以此类推。
3.超级拷贝
Hawk3.5增强了对拷贝功能的支持,使得操作更加简便。
不论是数据表列表,任务,模块或工作线程列表,都可以使用windows键盘快捷键shift+鼠标来多选,或使用ctrl+a全选,选择后即可执行删除和暂停等操作。
对于最常用的模块列表,右键即可拷贝当前所选的模块。已拷贝的模块支持如下功能:
- 可以直接粘贴到任何文本编辑器中,这在手动编辑xml工程文件时很有用。
- 拷贝到本任务或其他任务的任一模块的上侧或下侧
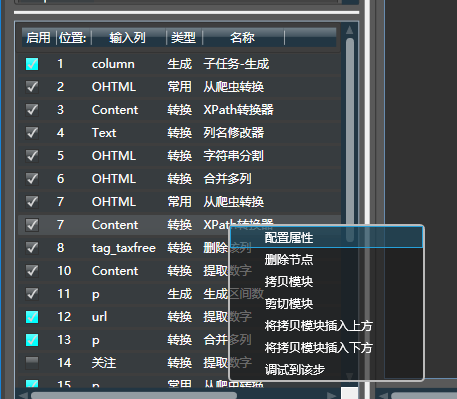
这带来了显著的好处,任务间能够更方便地共享配置和参数,方便重用。你亦可将配置拷贝到GitHub或其他社群中,方便他人定位问题。
4.线程管理
不论是调试还是执行模式,系统都会在任务管理视图中增加一个或多个线程。 你可以勾选,或取消勾选部分或全部线程,暂停或取消它们。当网站限制抓取时,可以暂停所有线程,等恢复后再次执行。
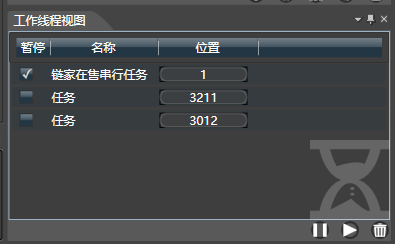
右下角分别是暂停,继续和删除任务。
注意:
- 当工作流有误时(比如该列所有数据都空,却在该列添加了 空对象过滤器,那么所有数据都会被过滤)可能不会产生任何数据输出。此时进度条并不会向前推进,产生卡死的假象。此时可强行将其删除
- 线程删除的流程是:先安全将其取消,如果线程无响应,则会直接将其杀死
4.1.单步调试
Hawk模仿了播放器和调试器,在调试模式下有步的概念,例如所在位置是6/20, 则说明总共有20个模块,只生效前面6个模块。 可以通过左右单击,或直接回退到开头、末尾来进行调试。
左侧显示了当前所有的模块,顺序和它们的输入输出列,双击上面的模块可对其进行配置,右键可删除。单选列表上的任一模块t,系统就会只仿真前t步的效果。 本质上,单步调试只是提取了工作流的一部分进行操作。 你可以在单步调试中,拖入新的模块。模块会自动插入在工作流中间。
有时为了在单步调试过程中查看模块的属性,可勾选界面右下角的调试详情,此时可直接显示当前模块的属性。

当模块有正常产出时, 模块的标志会变成蓝色,因此从上到下,第一个不是蓝色的模块,就有可能是有问题的模块。
5.运行模式
5.1.调试模式
在编辑任务的过程中,处于调试模式,它具备如下特点:
- 所有执行器都不工作,避免副作用
- 点击下方中间的刷新按钮,或修改配置,展示的数据会自动刷新
- 只能运行在串行模式上
- 所见即所得,只显示一定数量的数据(通过采样量修改)
- 可以禁用或启用某些模块,观察效果
- 会加入web请求和读取文件的缓存, 来提升预览速度(可能会导致一些问题)
- 输入列和输出列会用不同的颜色进行表示
在调试时,从爬虫转换模块可能会请求web数据,为了提升性能,该模块对请求做了缓存。保证数据只需获取一次,如果想强制刷新数据,将从爬虫转换模块禁用,再启用,原始缓存数据就会被擦除。

Hawk支持两种执行模式:
5.2.串行模式
只有点击执行时,才会切换到执行模式。执行时,可工作在串行模式/并行模式 在串行模式下, 所有任务串行执行,速度慢,但对网站压力小,不容易被封锁。为了进一步降低执行速度,可以设置延时时间,此时每次网络请求前,都会延时一定时间。 注意:
- 当执行器包含类似"向文件中追加内容"的操作时,强烈建议使用串行模式,因为Hawk没有加入多线程锁,有可能会导致冲突。
- 建议完成爬虫设计后,先进行串行模式,初步观察是否正确,之后再设置并行模式大量抓取。
5.3.并行模式
极大地加快了抓取速度,但很容易被封锁。 Hawk使用了线程池的机制,可以设置最大工作线程数,只有之前的工作线程完成工作,才会填入新的任务。否则过多的线程会迅速占用所有系统资源。
相比于Hawk2, Hawk3会自动分析可以并行的位置,因此多数情况下,直接运行就可以了。但是如果你想自定义并行化的行为,就需要阅读下面的内容。
5.4.并行化的原理
在调试模式下,所有获取都是串行的。而执行模式下,执行器才会执行。为了更好地理解并行化,强烈建议阅读下面的内容。
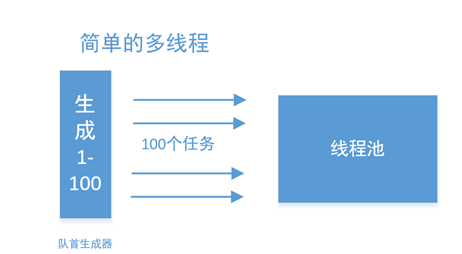
最简单的并行化
我们以抓取某个网站的100个页面为例,第一个模块生成区间数,可以生成1-100的页面,自然地,就可以创建100个任务,分别抓取了。
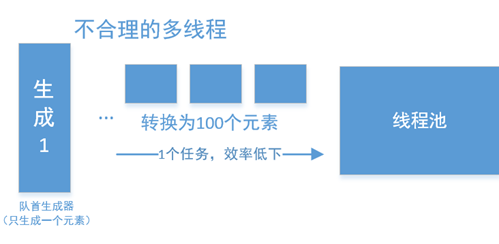
但是,但如果队首的生成器只生成了很少的元素,每个元素在后期,又会转换为大量的元素,那么这种方法就非常低下了。极端情况下队首生成器只生成一个元素,则并行化就毫无意义:
改进的并行
一种非常简单的思路,是将其切成两个任务,并行在任务中完成。
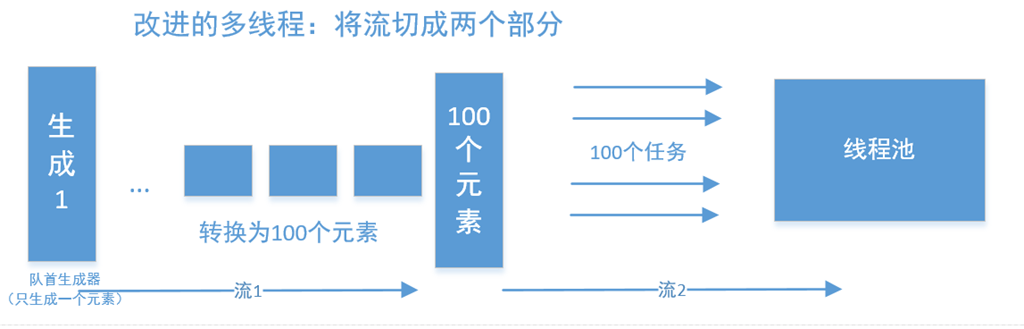
我们将其看成两个任务,第一个任务,负责产生出一堆种子任务出来,并加入到任务队列,之后再在这些种子的基础上,再分别调用第第二个任务。
如何切分任务?取决于你在任务中插入的启动并行的位置。这个位置就是切分为两个任务的“切割点”。
以大众点评为例, 北京有14个区县,有30种美食类型,如果直接在区县后插入并行,则只有14个子任务,任务数量太少:那么先通过任务1,获取420个元素,再以420个元素的基础上,插入并行,这样速度就快很多了。你也可以在14个区县之后插入并行化,那么就有14个子任务。
反过来,如果每个任务的工作量太少,比如只访问一次网站内容,则这样的种子创建并行就显得成本高昂,因此可以填写分组并行数量,比如10,那么Hawk就会以10个元素为一组,创建任务。
Hawk自动分析并行点
Hawk除了手工设置并行点,还能自动分析并行点,那么并行点是不是越靠后越好呢?不是的,这样分的太细,每个任务要处理的数据特别少:依赖于批量执行的模块会有性能损失: 例如写入数据库,批量插入100条数据速度很快,但按条插入就不快了。
但若尽量靠前,则任务分得特别粗,在断点续跑时,任务需要更多的时间达到相同的位置(这点不够直观,可以理解为层级越多,则进行查找所需的步数越少)
目前Hawk采用了尽量靠后的策略,未来可能会在这方面变得更加智能。