案例1_链家
链家的同学请原谅我,但你们的网站做的真是不错。
1.设计网页采集器
我们以爬取链家二手房为例,介绍网页采集器的使用。首先双击图标,加载采集器:
在最上方的地址栏中,输入要采集的目标网址,本次是http://bj.lianjia.com/ershoufang/。并点击刷新网页。此时,下方展示的是获取的html文本,目前工作模式默认是List。

原始网站页面如下:
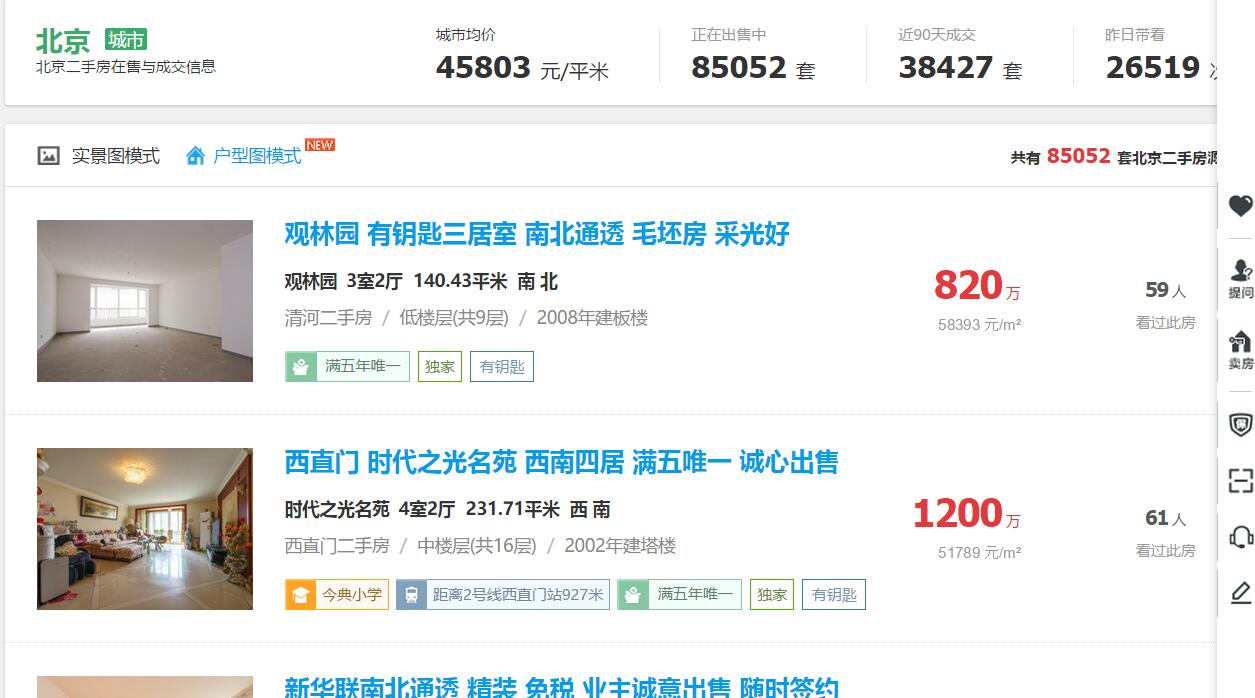
此时,有两种做法来获取想要的房产数据:
1.1.全自动嗅探:手气不错
直接无脑点击手气不错,弹出下面的界面:
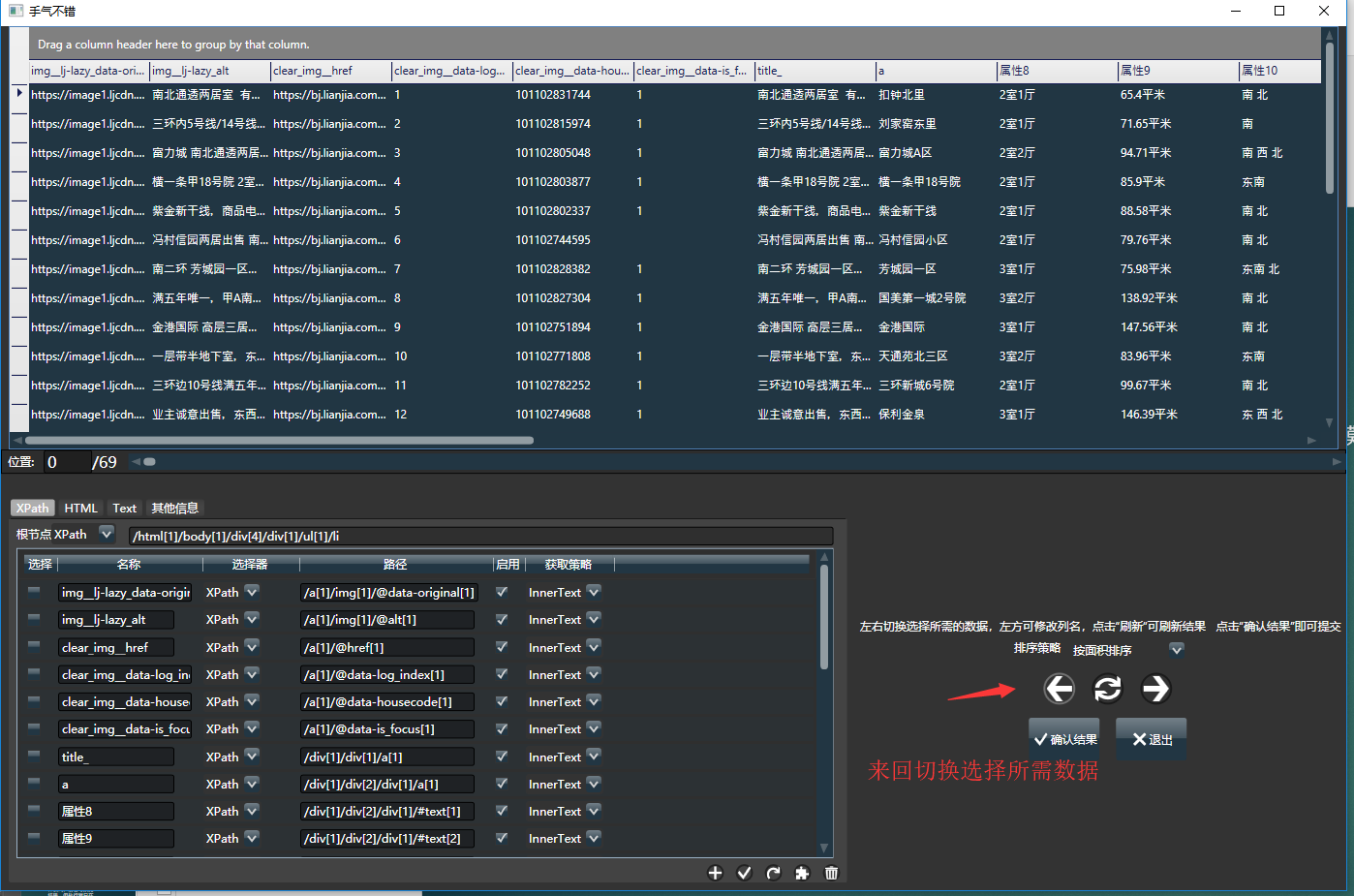
对于链家这个例子,你可以修改每个列对应的名字,如房价,总面积等。或者更懒一点,直接点击确认结果即可。
Hawk3的手气不错功能得到大大加强,大部分手工操作已经不需要了。
1.2.手动模式
在一些情况下,由于软件不知道到底要获取哪些内容,因此需要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。
以上述页面为例,通过检索820万和51789(单价,每次采集时都会有所不同),我们就能通过DOM树的路径,找出整个房源列表的根节点。
下面是实际步骤
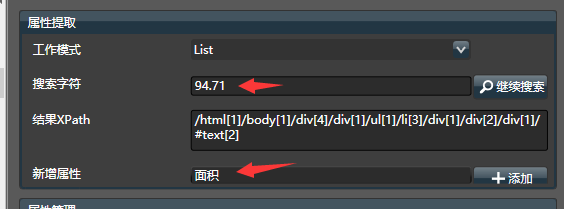
由于要抓取列表,所以读取模式选择List。 填入搜索字符94.71, 发现能够成功获取XPath,左边的源代码框会自动跳转到对应位置, 编写属性为“面积” ,点击添加,即可添加一个属性。类似地,再填入303,设置属性名称为“总价”,即可添加另外一个属性。
如果发现有错误,可点击编辑集合, 对属性进行删除,修改和排序。
你可以类似的将所有要抓取的特征字段添加进去,或是直接点击手气不错,系统会根据目前的属性,推测其他属性:
属性的名称是自动推断的,如果不满意,可以修改列表第一列的属性名,点击刷新后更新。
工作过程中,可点击提取测试 ,随时查看采集器目前的能够抓取的数据内容。这样,一个链家二手房的网页采集器即可完成。可在网页采集器最上方,修改采集器的模块名称,这样就方便数据清洗任务调用该采集器。
2.设计数据清洗
2.1.构造url列表
在上一节介绍了如何实现一个页面的采集,但如何采集所有二手房数据呢? 这涉及到翻页。
还是以链家为例,翻页时,我们会看到页面是这样变换的:
http://bj.lianjia.com/ershoufang/pg2/
http://bj.lianjia.com/ershoufang/pg3/
…
因此,需要构造一串上面的url. 聪明的你肯定会想到, 应当先生成一组序列, 从1到100(假设我们只抓取前100页)。
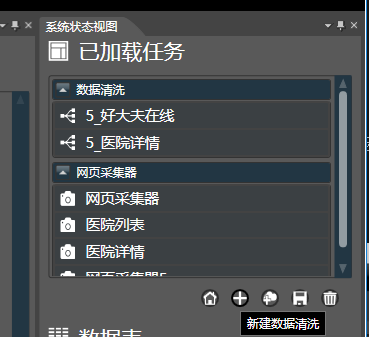
- 除了在软件的欢迎页面上双击数据清洗,也可以
系统状态视图中已加载任务列表下,点击加号,快速创建新的任务:
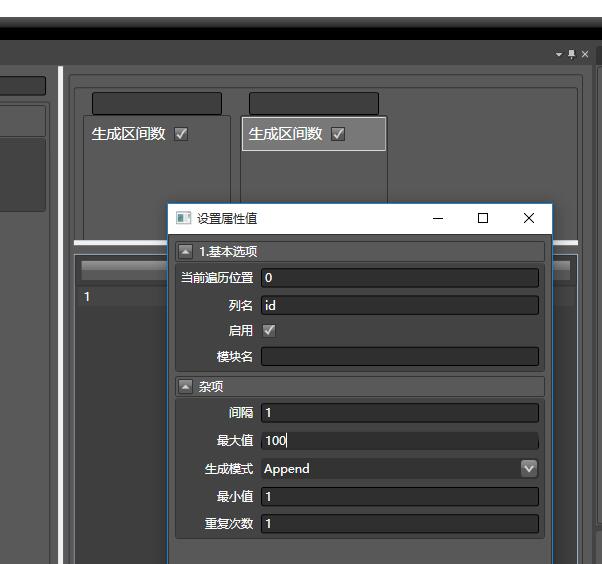
在左侧的搜索栏中搜索生成区间数, 将该模块拖到右侧上方的栏目中:
-
在右侧栏目中双击生成区间数,可弹出设置窗口, 为该列起名字(id), 最大值填写为100,生成模式默认为Append: 为什么只显示了前20个? 这是程序的虚拟化机制, 并没有加载全部的数据,可修改采样量(默认为20)。
-
将数字转换为url, 熟悉C#的读者,可以想到string.format, 或者python的%符号:搜索合并多列,并将其拖拽到刚才生成的id列, 编写format为下图的格式,即可将原先的数值列变换为一组url
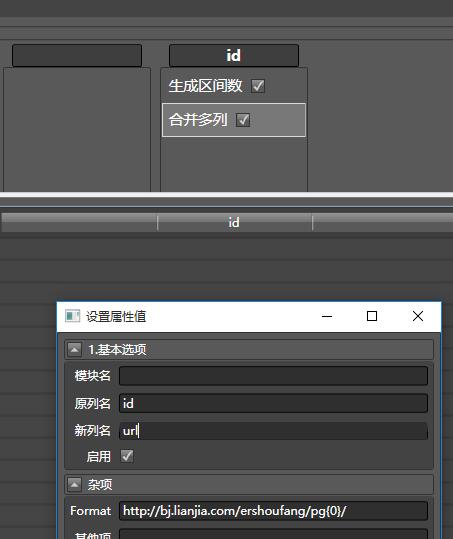
(如果需要多个列合并为一个列, 则在“其他项” 栏目中填写其他列的列名,用空格分割, 并在format中用{1},{2}..等表示)
(由于设计的问题,数据查看器的宽度不超过150像素,因此对长文本显示不全,可以点击单元格弹出对应完整文本。
3.调用网页采集器
生成这串URL之后,我们即可将刚才已经完成的网页采集器处理这串url。
拖拽从爬虫转换到当前的url,在爬虫选择 栏目中选择刚才配置的采集器名称。
(不少朋友在此处出现问题,需要在从爬虫选择模块中,填写你配置的网页采集器名称,如果没有修改,则默认就是网页采集器)
之后,系统就会转换出爬取的前20条数据:
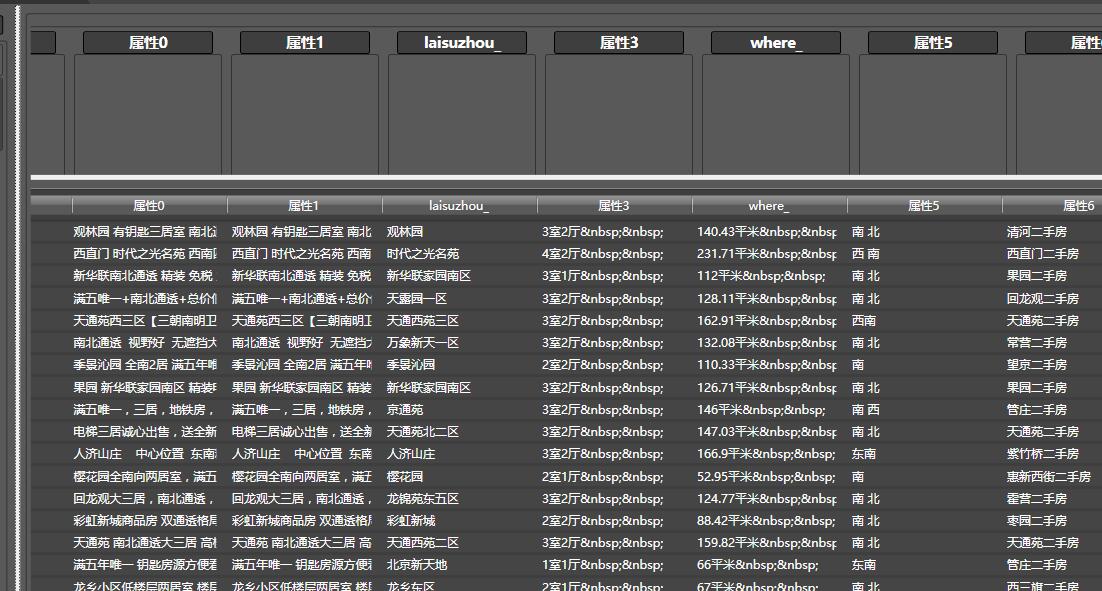
可以看到, 数据中“属性3” 列包含html转义符,
拖拽html字符转义,到属性3列,即可自动转换所有转义符。
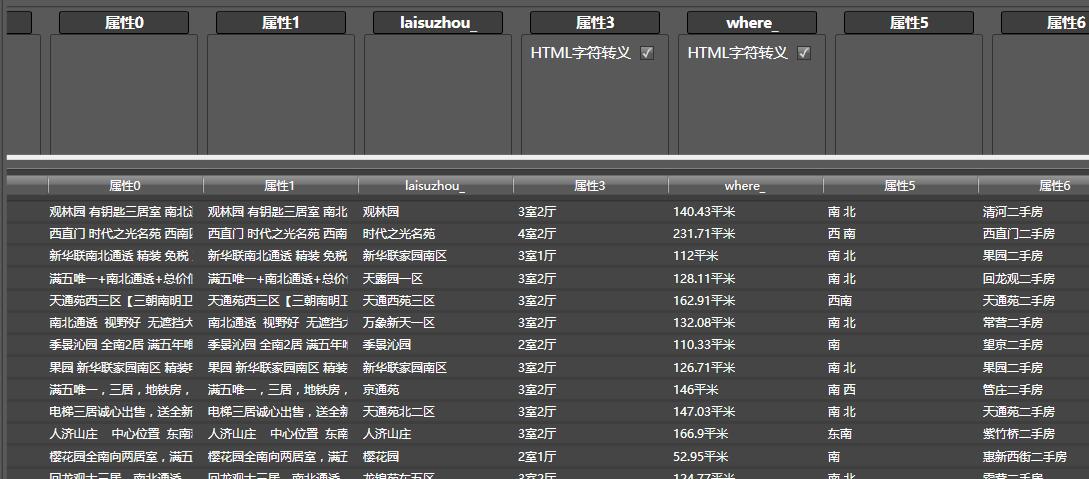
如果要修改列名,在最上方的列名上直接修改, 点击回车即可修改名字。
where(面积)列中包含数字,想把数字提取出来,可以将提取数字模块拖拽到该列上,所有数字即可提取出来。
类似地,可以拖拽字符分割或正则分割 到某一列,从而分割文本和替换文本。此处不再赘述。
有一些列为空,可以拖拽空对象过滤器 到该列,那么该列为空的话会自动过滤这一行数据。
4.保存和导出数据
需要保存数据时,可以选择写入文件,或者是临时存储(本软件的数据管理器),或是数据库。这就是执行器的作用。
执行器代表一些有副作用的模块,在调试模式中它们不会执行,只有在运行时才会生效。
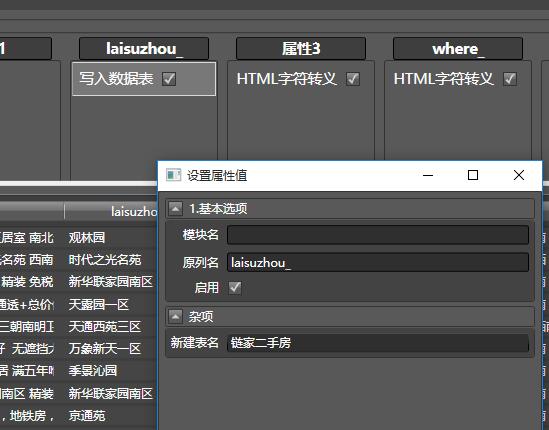
拖写入数据表到任意一列, 并填入新建表名(如链家二手房)
下图是这次操作的所有子模块列表:
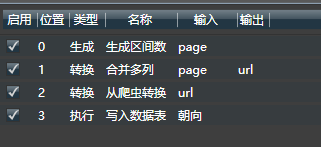
之后,即可对整个过程进行操作:
选择串行模式或并行模式, 并行模式使用线程池, 可设定最多同时执行的线程数(最好不要超过100)。推荐使用并行模式,

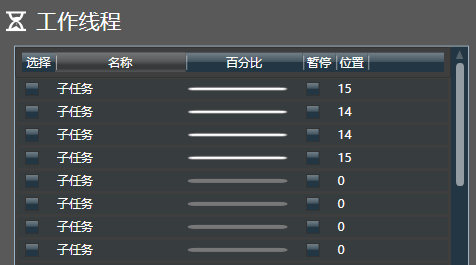
点击执行按钮,即可在任务管理视图中采集数据。
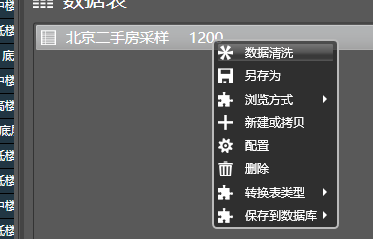
之后,在数据管理的数据表链家二手房上点击右键, 选择另存为, 导出到Excel,Json等,即可将原始数据导出到外部文件中。
类似的, 你可以在清洗流程中拖入执行器,则保存的是中间过程,也可以在结尾拖入多个执行器,这样就能同时写入数据库或文件, 从而获得了极大的灵活性。
5.保存任务
在系统状态视图的已加载任务上点击右键,保存任务,即可在欢迎页面中保存新任务(任务名称与当前模块名字一致),下次可直接加载即可。如果存在同名任务, 则会对原有任务进行覆盖。
在已加载任务的空白处,点击保存所有模块,会批量保存所有的任务。同样,你可以试着将不同的任务拖拽到下面的图标上,分别可复制,保存和删除任务。
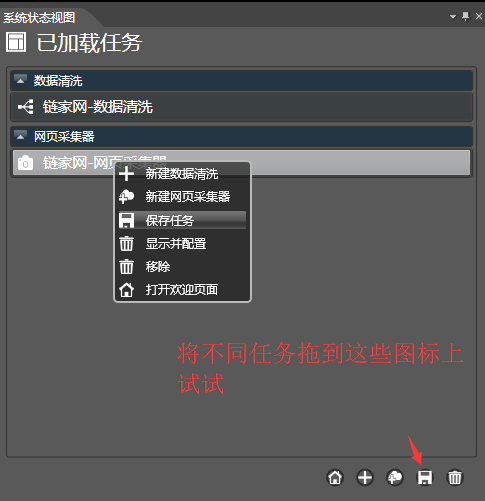
你可以将一批任务,保存为一个工程文件(xml),并在之后将其加载和分发。
这就是Hawk入门的第一篇教程,尽量简单,不涉及复杂操作。