案例3_百度百家新闻
百度百家已死,百家号这样的害人产品横空而来,本教程已无效
本例子你将学会:动态页面的抓取。
目标地址:
http://baijia.baidu.com/
这是典型的瀑布流例子,不论向下翻多少页,浏览器的地址是不会发生变化的。我们可以断定它使用了ajax。
我们翻到第二页(为什么要翻到第二页的原理,可参考3.1动态嗅探。),找一个比较有代表性的关键字:
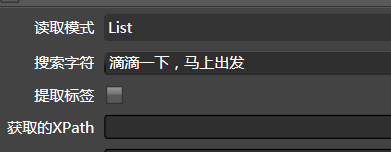
滴滴一下,马上出发
将其拷贝到网页采集器的搜索字符里:
Hawk会弹出提示对话框:
//补充图片
已经提醒如下内容:
2016-10-12 08:41:44 WARN 在该网页中找不到关键字 滴滴一下,马上出发,可能是动态请求,可以启用【自动嗅探】,勾选【转换动态请求】,并将浏览器页面翻到包含该关键字的位置
点击确认后, 浏览器会弹出百度百家的页面,你可以将滚动条往下翻,直到出现那篇滴滴的文章。之后Hawk会弹出对话框:
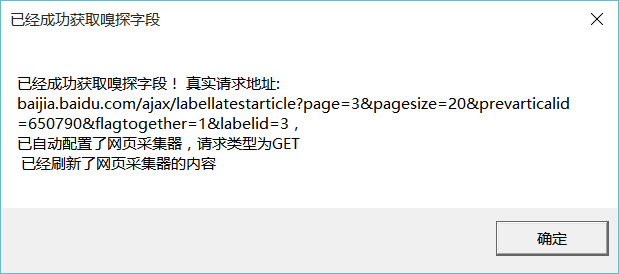
此时,Hawk会自动关闭嗅探。之后,再点手气不错,即可看到完整的页面内容,也可以按照关键词搜索,和其他静态网页的使用完全一致。
再打开请求详情,发现Hawk已经将页面的cookie获取到了。注意到真实的地址:
http://baijia.baidu.com/ajax/labellatestarticle?page=3&pagesize=20&prevarticalid=650790&flagtogether=1&labelid=3
你可以像以往合并多列的方法,来获取所有页面,此处不再赘述。