快速教程
本文给不想看详细教程的同学使用,仔细阅读,可以让你战斗力爆棚:
1.界面和交互
1.1.主工作区
启动后,在欢迎页面有三个tab页: 新建任务,任务市场和参数设置。欢迎页面非常重要,能够新建任务,或者浏览相关文档和帮助。
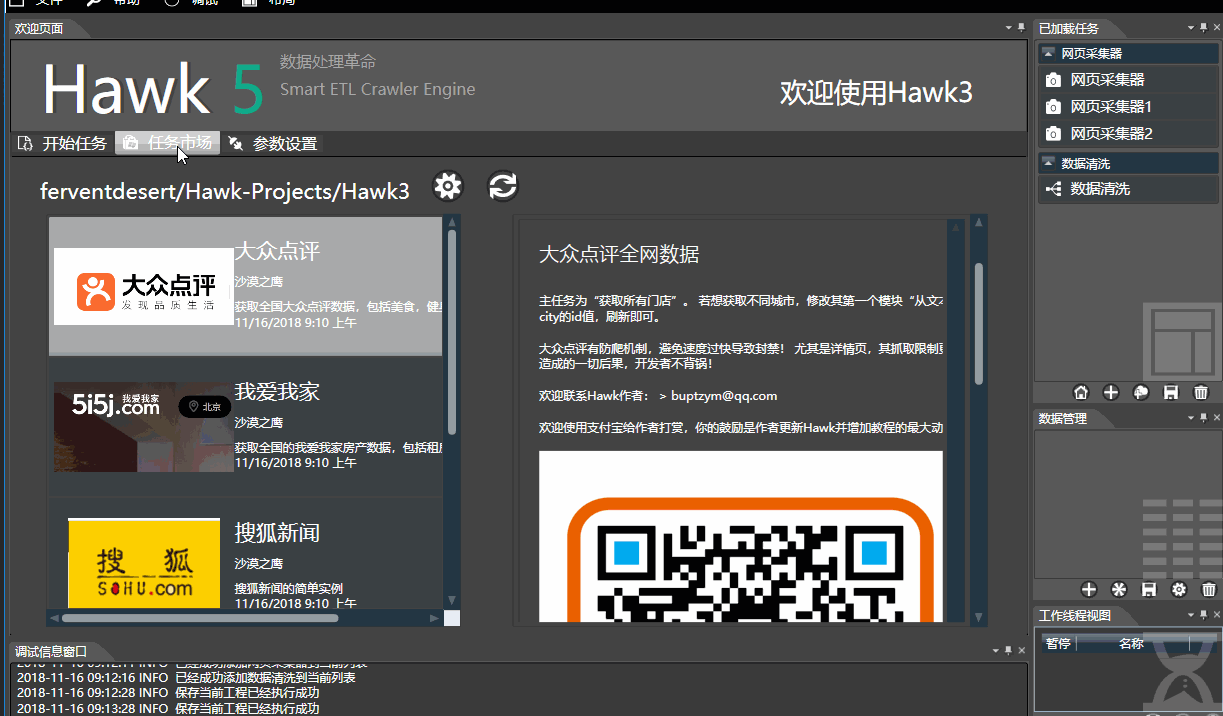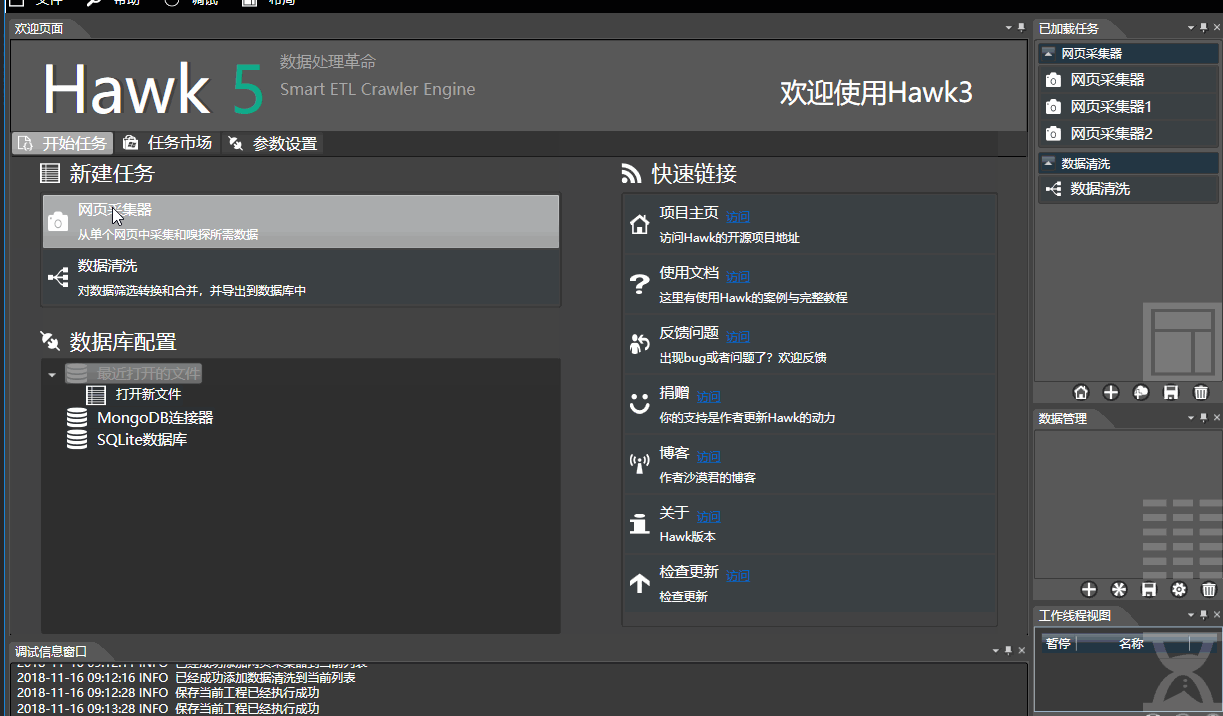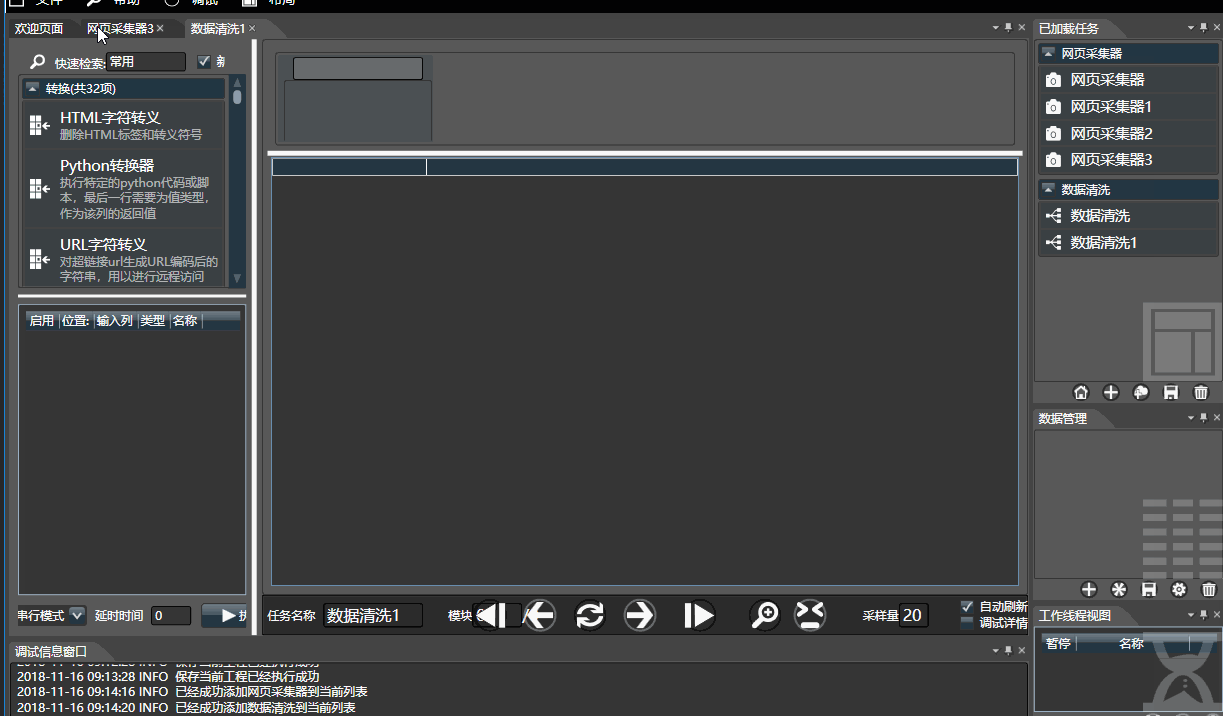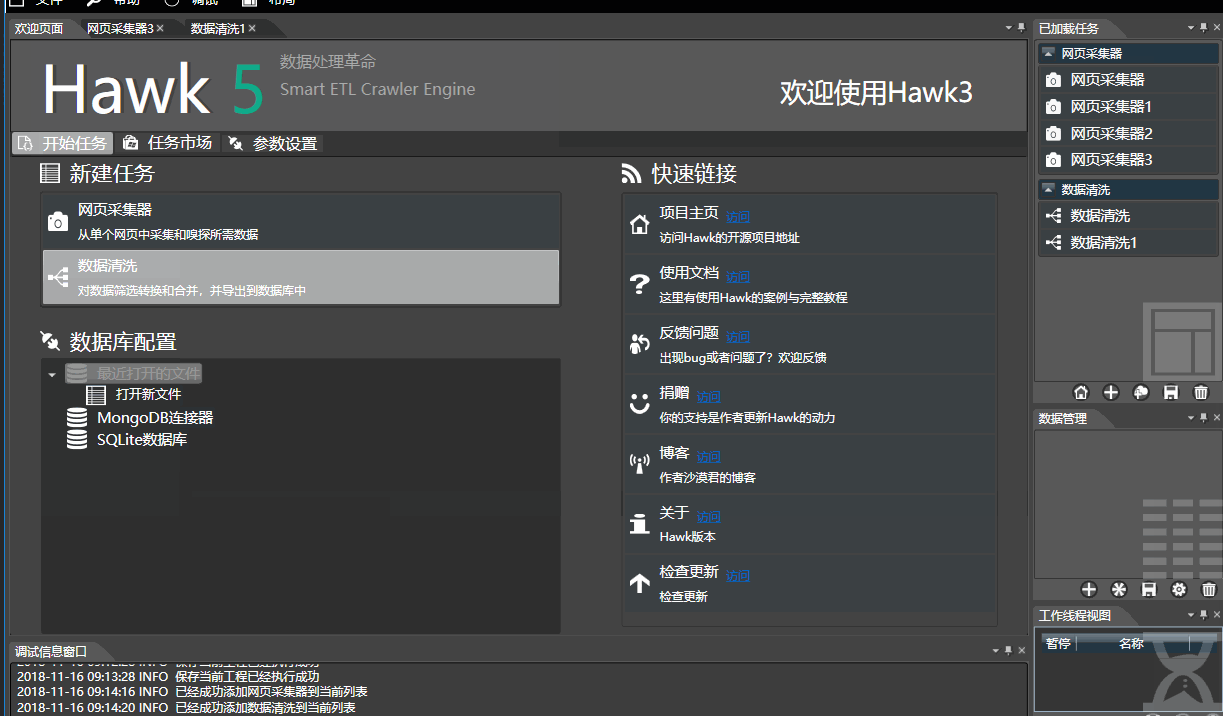
- 新建任务:双击图标即可新建和加载已有任务
- 点击tab菜单【文件】可加载,保存任务,任务为xml文件。
- 下侧是【数据管理】,空白处右键可新建连接,连接名上右键可配置,支持本地文件(xls,txt,json),数据库(mongodb,sqlite)。数据库需要连接后才能使用,可勾选【自动连接】.
1.2.状态区
在Hawk主界面右侧是当前的状态,包括三个区域:
- 已加载任务
- 数据管理:可显示生成的或从文件中导出的表
-
工作线程视图:正在执行的任务都会显示在这里
-
软件右下角对应的是【系统状态视图】,左右侧分别是已加载的任务和数据集。 左键查看,右键配置,空白处右键批量管理。 下面的图标可用于删除,拷贝,保存等功能,把任务或数据集拖到图标上试试!
- 【网页采集器】用于配置单个网页的抓取规则,【数据清洗】用于打造清洗流程,并调用前者。 复杂任务会创建多个清洗并互相调用。
2.网页采集器
网页采集器 模拟了浏览器的设计,填入网址,点击刷新,即可获取对应地址的html源码。
认识到网页是一棵树(DOM)后,每个XPath对应一个属性,即可从网页上获取单个或多个文档。网页采集器的目的就是更快地通过手工或自动配置找到最优XPath。
2.1.工作模式
使用采集器,首先要按照抓取的目标,选择合适的工作模式:
- 多文档: 会输出多份文档,通常在网页的列表页中使用, 如二手房的列表页面,新闻的列表页
- 单文档: 输出单份文档,一般在网页的详情页中使用,如京东的订单页,新闻
- 不进行转换: 直接输出网页源代码,放置于Content列中
注意:
- 一个复杂的页面可能包含多个列表和详情,因此模式的选择主要取决于要抓取的数据是什么
- 当在 多文档或 单文档模式,且属性数量为0时,也和 不进行转换行为一致
2.2.基本操作
- 左侧的区域,显示了html源码和浏览器视图(但不能执行js),可通过上侧tab页切换。
- 右侧是配置区域,可对关键字进行搜索,并对所有的属性进行管理。
- 点击【提取测试】,可预览检查配置结果。
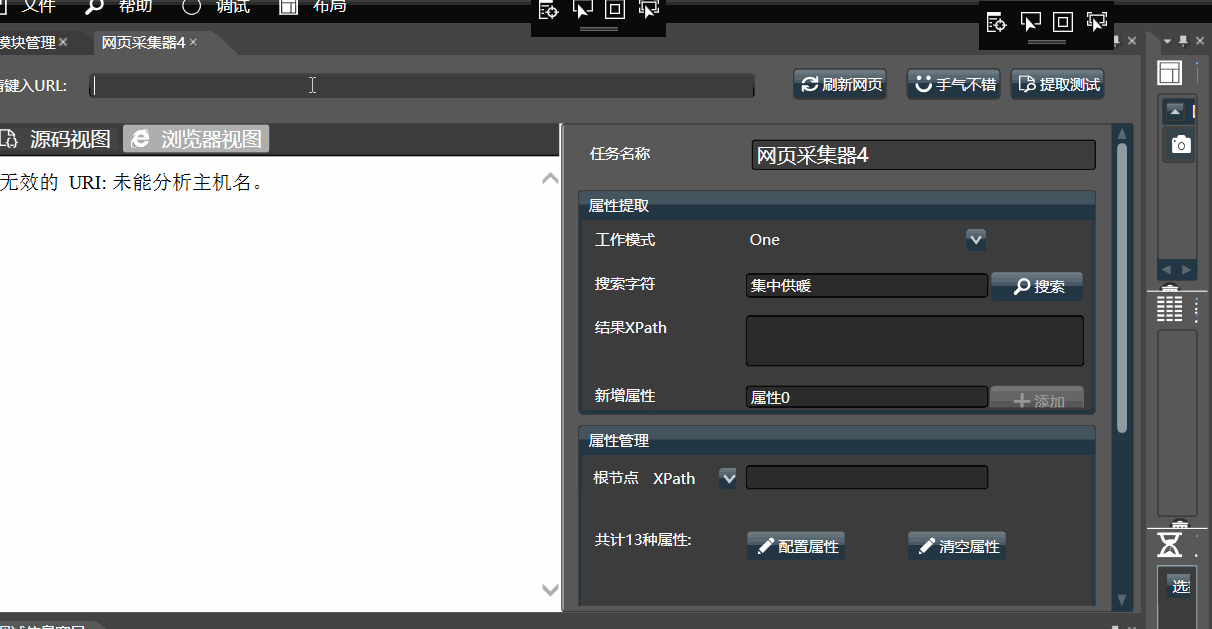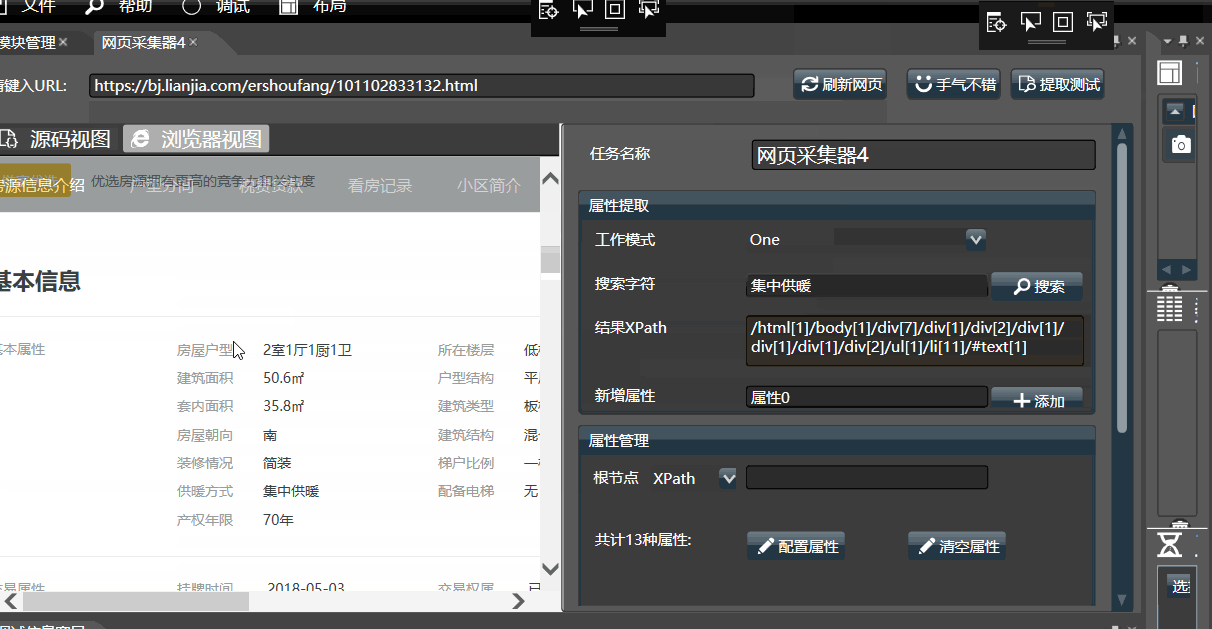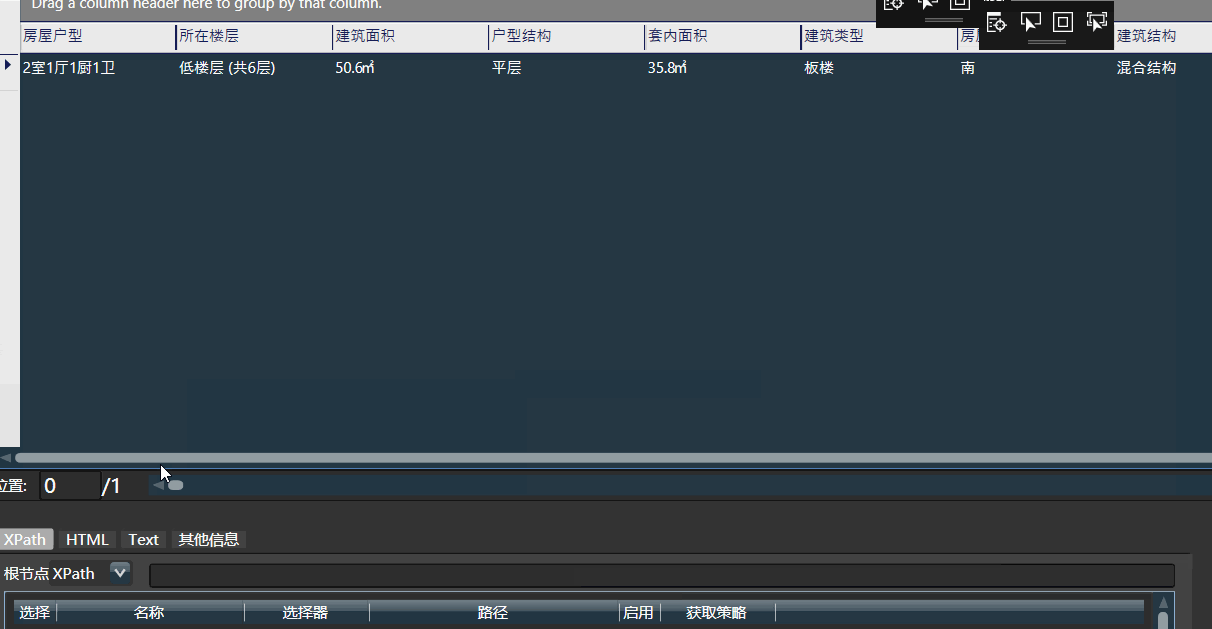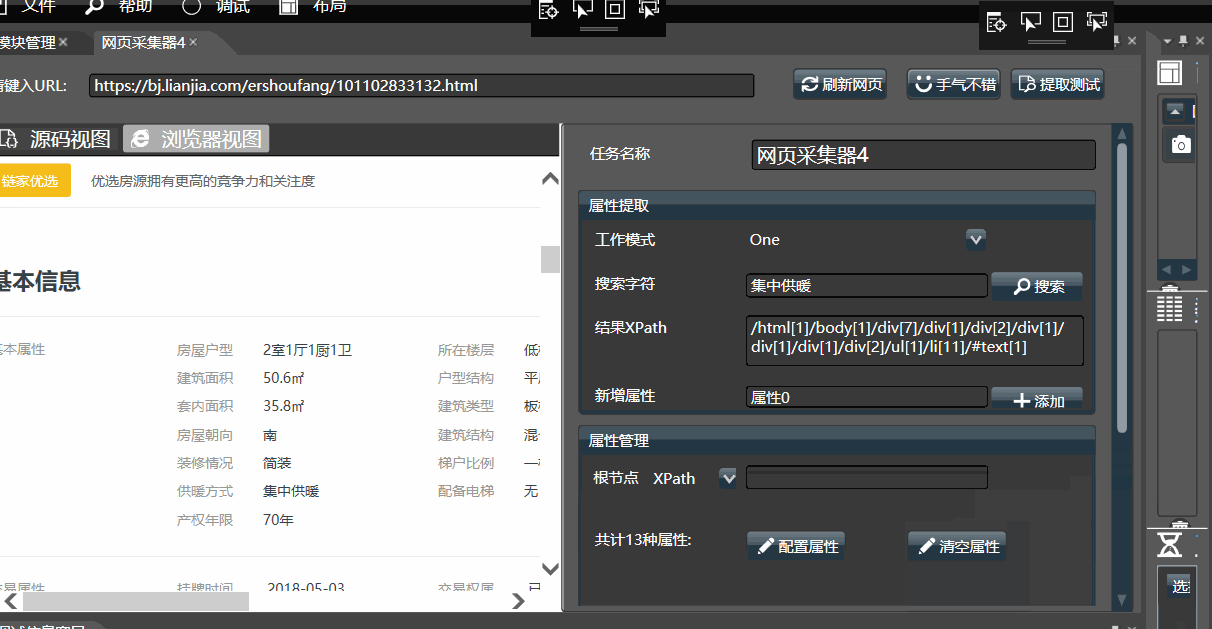
在多文档模式下,通常直接点击右上角的手气不错,在弹出的结果下选择所需数据,可配置其名称和XPath。点击确定即可配置完毕。即可自动获取绝大多数网页的目标内容。
可手工填入搜索字符,即可在网页上快速定位元素和XPath,可在多个结果间快速切换,找到所需数据后,输入属性名称后手工添加属性。
2.3.高级功能
- 点击【Http请求详情】,可修改网页编码,代理,cookie和请求方式等,网页出现乱码可用
- 若希望自动登录,或获取动态页面(ajax)的真实地址,填入搜索字符,点击【自动嗅探】,在弹出的浏览器中翻到对应的关键字,Hawk就能自动捕捉真实请求
- 超级模式下,Hawk会将源码中的js,html,json都转成html,从而使用手气不错, 更通用但性能较差
- 填写【共享源】,本采集器同步共享源的【Http请求详情】,避免重复设置cookie代理等。
- 详情页(单文档模式)也可以手气不错(Hawk3新功能),搜索所需字段,不需要添加到属性列表,点击手气不错试试!
- 网页地址也可以是本地文件路径,如D:\target.html, 用其他方法保存网页后,再通过Hawk分析网页内容
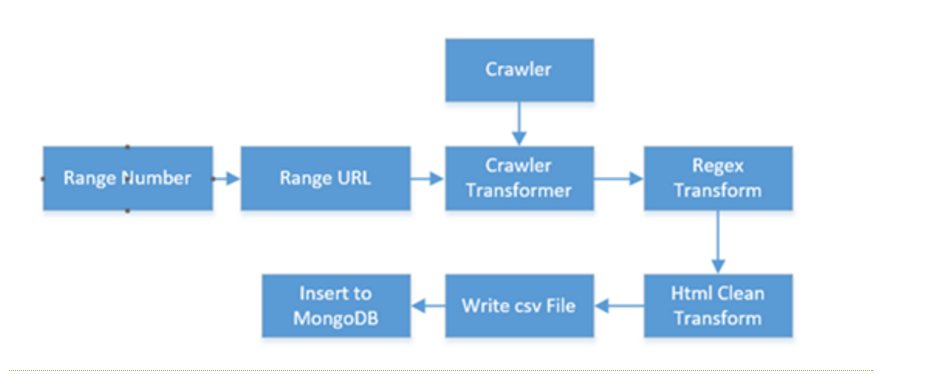
3.数据清洗
数据清洗可以通过组合多个不同的子模块,生成多样的功能,通过拖拽构造出一个工作流,它能够产生一个有限或无限的文档序列。比如下面:
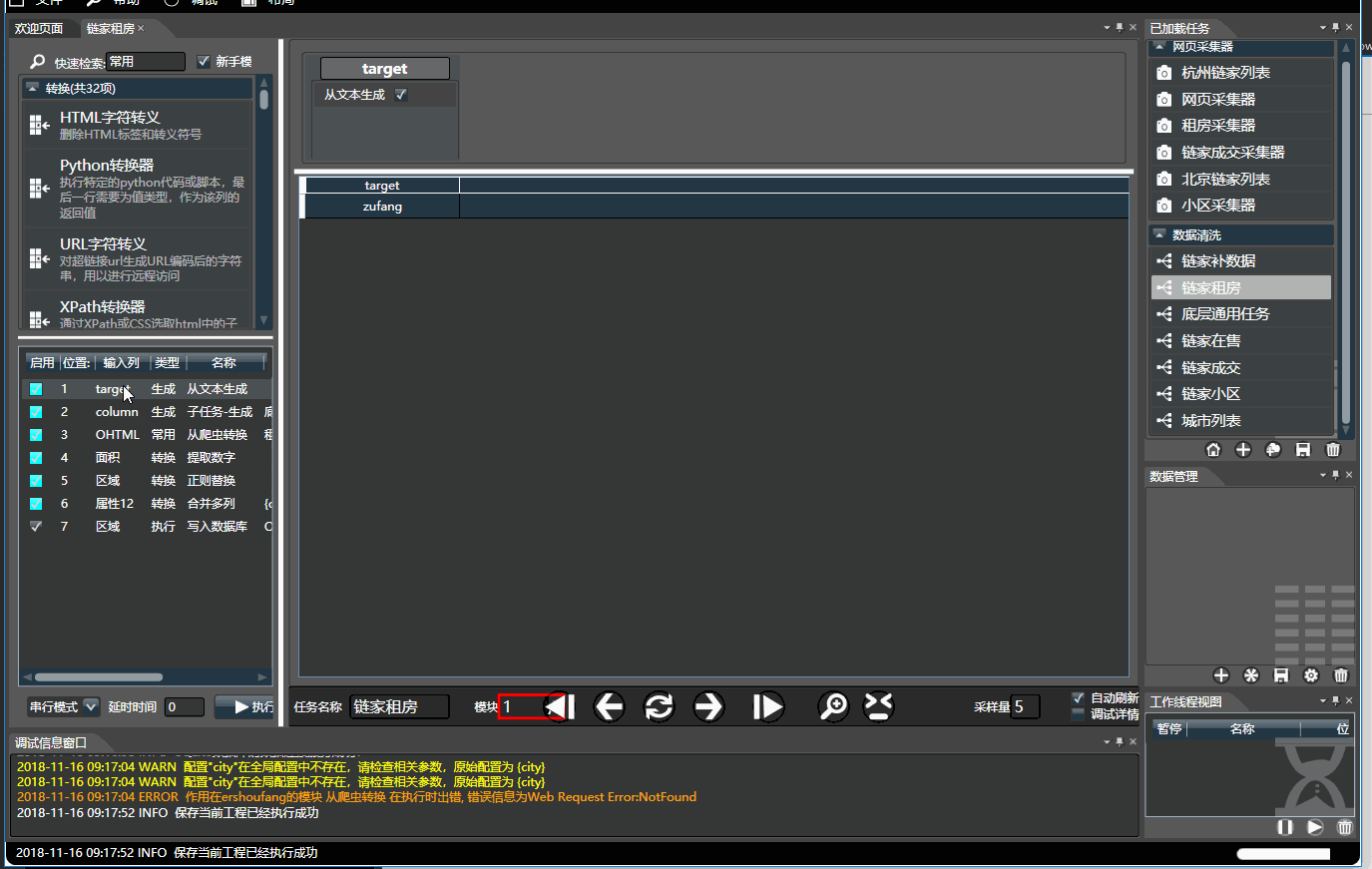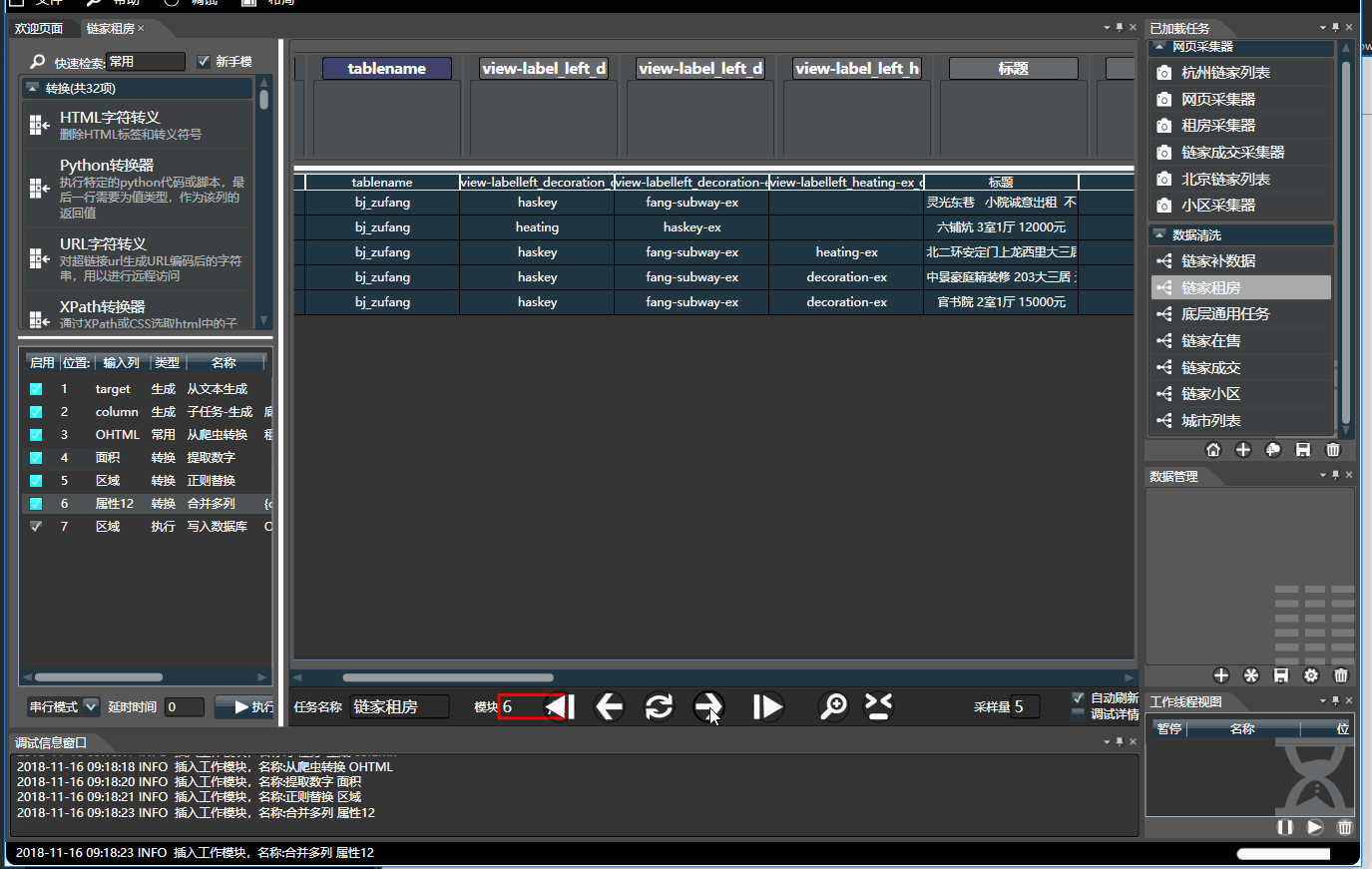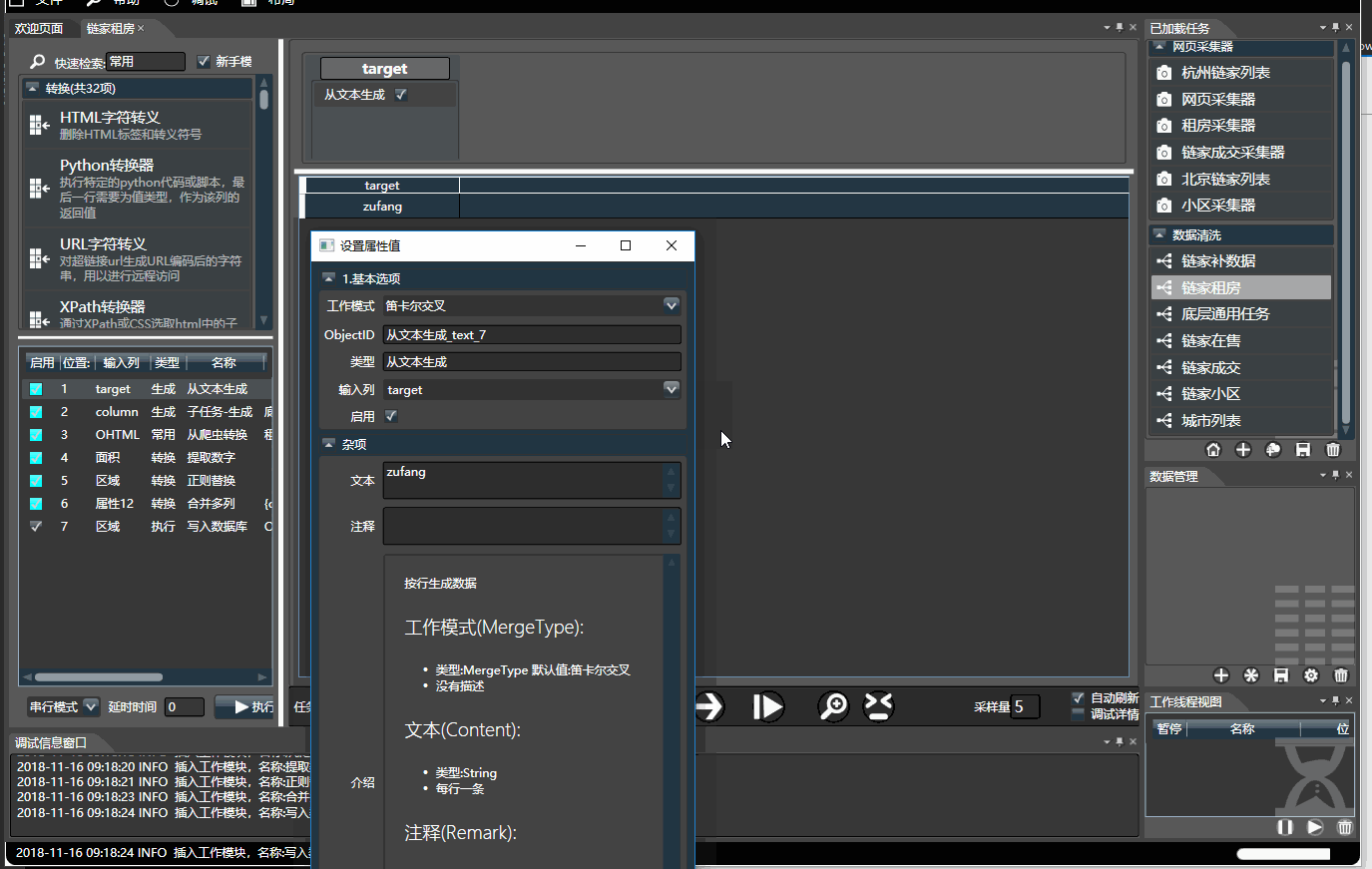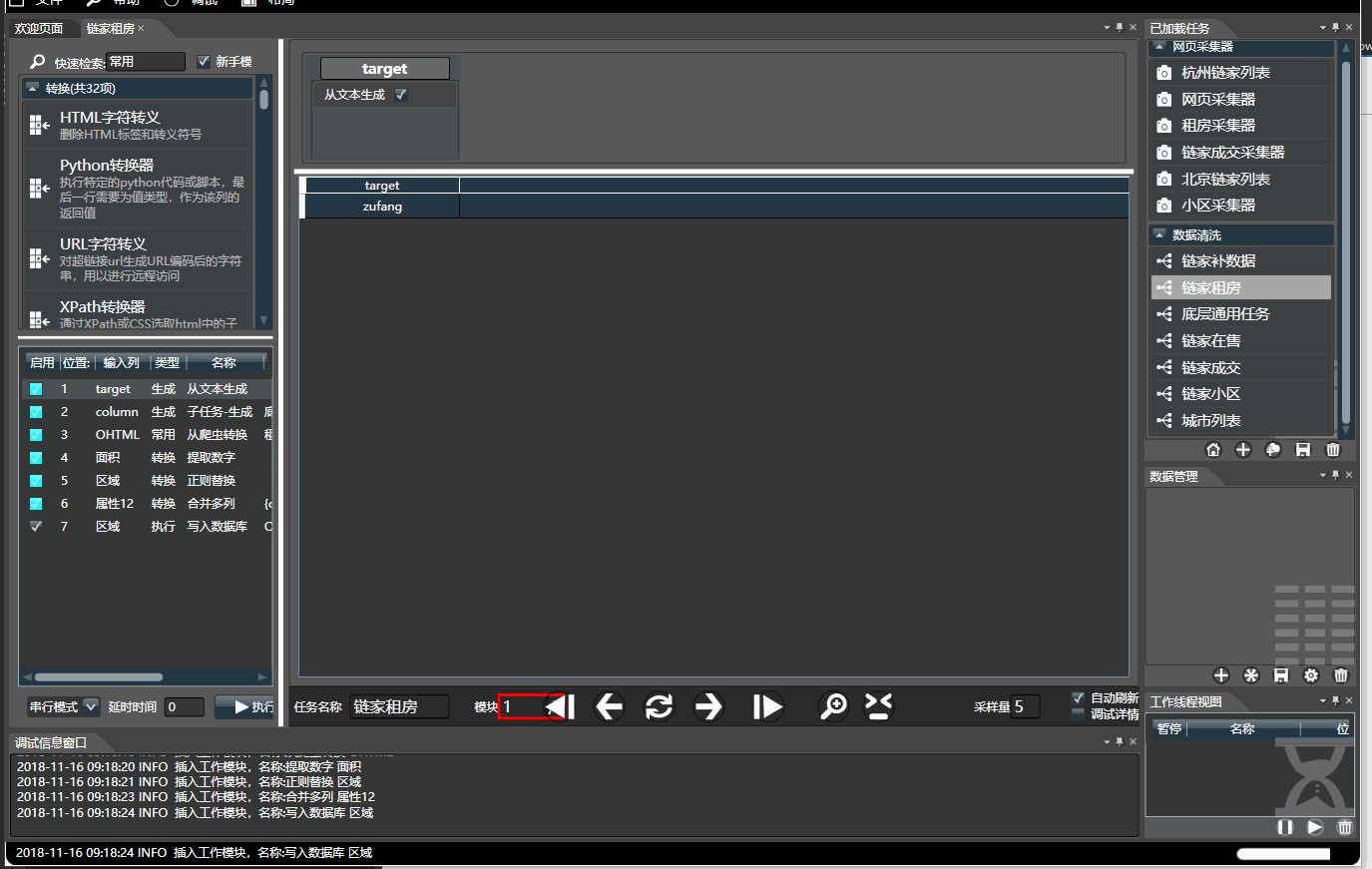
3.1.基本操作
- 左侧是所有模块列表,分为生成,转换,过滤和执行四种类型,可通过名称和拼音首字母快速检索。顺序组合可构成复杂任务。
- 右侧是数据预览,可将左侧选中的模块拖入到右侧对应列上。 双击每个列上面的模块对其配置。将鼠标停靠字段上可查看使用介绍
- 预览时,处理是串行的,数据不会被写入,有缓存,调试所见即所得。 只有在执行模式下才会并行快速执行。
- 执行器可看做带有副作用(如写入文件)的转换器,只有在执行时才会运行
- 生成器通常位于任务开头,可从文本,文件,数据库读取数据。生成器也能位于流的中间,通过多种模式与已有数据流组合
- 下方菜单栏可点击刷新,前后单步,可通过采样量来修改预览的数据量。配置完毕无误后,左侧面板点击执行即可。
- 很多问题来自于模块顺序不对,任何步骤错误,会导致连锁的问题,因此有必要使用单步调试,在调试到某步时,拖入的模块会插入到所在位置。
3.2.高级功能和技巧
- 输入列一般不用配置,需要时可下拉选择,也可手工输入文本。列名不要为纯数字,否则无法正常显示。
- 关于Python转换器:最后一行必须是可求值的表达式。例如有两列a,b,转换器输出列为c,表达式为a+b,则c列内容就是a+b。但表达式不能写c=a+b; Python是强类型语言,输入的数据可能是字符串或数字,因此必要时需要做类型转换;通过填写库路径,可让转换器调用第三方模块。
- 可在任务的各个位置拖入多个执行器(如【写入数据表】),它保存的是当前状态的数据。
- 子任务:任务可互相调用,功能非常强大,可用于处理多次跳转,详情页还包含列表的问题,比较复杂,需参考相关文档。
3.3.对配置的约定
- 具体数值,直接填入配置框即可
- 涉及到输入多个列名,多个分隔符等,都默认用空格分割,例如
a b c - 当希望从本
数据清洗中读取其他列的数据到本参数,使用方括号表达式,例如[col] - 当希望从全局配置中读取特定字段时,使用大括号表达式,例如
{YOUR_CONFIG} - 希望将多个列的数据合并作为参数时,可先使用
合并多列,再使用对应的表达式 - 配置子任务的模块范围时:
1:100表示从1到100,2:-2表示从第2个模块到倒数第二个模块,可参考Python的slice写法 - 配置子任务的字段映射时,可以用
a:b c:d表示a列映射到b列,以此类推。
4.一些忠告
- Hawk除了做爬虫,还能做数据清洗,甚至批量执行命令,需要你来挖掘。
- Hawk对代理的支持不够(免费的就知足吧),避免过度抓取导致屏蔽。
- 记得经常保存任务,尽量将数据写入到数据库而非表里,否则程序可能崩溃难以挽回。
5.如何提问
Hawk是个免费的系统,因此没有客服mm(谁请得起,设计者也不够帅),因此好的问题能极大地提升解决问题的速度。请按照如下方式描述你的问题:
- 抓取的网站地址,要抓取什么内容,在页面的什么位置,是什么范围。
- 如果能提供你的工程文件,可在附录中给出,这能最大程度解决问题。
- 如果是界面出现异常,请提供在什么环境下,点击什么按钮,报出什么异常,并发送所执行文件夹的log.dat日志文件作为附件。
- 操作系统版本,.Net Framework环境(不是必须)
请尽量避免如下提问方式,这样的提问没有任何意义,作者也无法解决你的问题:
- XXX网站怎么爬
- XXX不会用,用不了
- XXX出问题了
提问按照如下优先级进行:
- 推荐使用Github的issue,方便其他朋友查阅已有的问题。: https://github.com/ferventdesert/Hawk/issues
- 加入QQ群: 546750531(Hawk数据抓取交流)
- 给作者发邮件: buptzym@qq.com